
noindex 是一個 SEO 很常見、實用的標籤,noindex 標籤可以讓搜尋引擎「不要索引」網頁。

noindex 是一個 SEO 很常見、實用的標籤,noindex 標籤可以讓搜尋引擎「不要索引」網頁。
但如果 noindx 設定錯誤的話,對於網站 SEO 成果會有毀滅性的影響。
接下來我會分享 noindex 的意思、使用方法、注意事項,幫助你全面了解 noindex。
noindex 是一種用來告訴搜尋引擎「不要將此頁面納入搜尋結果」的指令。
它通常出現在網頁的 meta 標籤(<meta>)中,或者透過 HTTP 標頭的方式(x-robots-tag)傳達給搜尋引擎。
由於搜尋引擎大多會尊重這樣的設定,因此當你在網頁中加入 noindex,代表你不希望這個頁面出現在搜尋結果中。
和 robots.txt 不同的是,noindex 不會阻擋爬蟲抓取頁面,而是明確指示搜尋引擎「拜訪可以,但不要顯示在搜尋結果」。
延伸閱讀:《robots.txt 介紹:什麼是 robots.txt?》
noindex 就像你在門口貼了一張「請別把這裡的東西『帶走』」的告示,這個『帶走』就是索引、呈現在搜尋結果上上。
搜尋引擎(好比 Google)走進來看到這張告示,就知道「哦,這些內容我可以看看、可以知道它是什麼,但是不能把它放到搜尋結果裡面」。
也就是說,你還是讓搜尋引擎來看看你的網頁,但明確告訴它:「不要出現在搜尋結果列表」。
如果你完全不想被任何人翻閱,那就要用更嚴格的保護方式(像密碼鎖),不僅僅只是貼「noindex」。
noindex 的重點不是「擋掉爬蟲來看」,而是「不要被放到搜索結果」。
舉例來說:
延伸閱讀:《SEO 自學大全:一篇就搞懂 SEO,完整說明 SEO 的底層邏輯》
工商時間
如果你想要更系統化、更輕鬆的學好 SEO,推薦你參考我與知識衛星合作的 SEO 線上課程《SEO 排名攻略學:從產業分析到落地實戰,創造翻倍流量》。
這是我的 SEO 集大成之作,讓你從入門到精通,附贈實戰模板跟檢核表,讓你真正學好 SEO。

有時候,你可能不希望某些頁面被搜尋引擎收錄,卻又不想完全阻擋爬蟲進入網頁(例如需要爬蟲抓取連結、瞭解頁面結構,但結果頁不希望曝光)。
此時 noindex 指令就能派上用場。
大型網站常有重複或極度相似的頁面,使用 noindex 能避免搜尋引擎判斷為重複內容,導致排名受影響。
若你在測試網站新功能,但還不想要被大眾搜到,就能先為該測試頁面加上 noindex。
有些不具價值或功能性較低的頁面,索引對整體 SEO 幫助不大,如 tag 頁面、低價值頁面、薄內容、過時的內容、不重要的內容。
此時透過 noindex,讓搜尋引擎將更重要的頁面排在前面,也就是排除掉低價值的頁面。
行銷頁面若已活動結束,但還想保留頁面做數據分析,不打算持續曝光在 SERP(搜尋引擎結果頁),就能透過 noindex 讓搜尋引擎知道「不要繼續收錄」。
透過上述做法跟概念,noindex 能讓搜尋引擎不去爬取這些不太重要的頁面,進而「間接」讓爬取預算(crawl budget)可以被更有效利用。
但利用 robots.txt 控制爬取,會是更有效的做法。
在 HTML 中,最常見的做法是使用 <meta> 標籤設定 robots 屬性,如下所示:
<head>
<meta name="robots" content="noindex, follow">
</head>
參數說明
noindex, nofollow。有些情況下,你也可以透過伺服器端的 HTTP 標頭設定 x-robots-tag: noindex。
這尤其適用於非 HTML 文件(例如 PDF)想要排除在搜尋結果之外的情境。
假設你的網站有一個「搜尋結果頁」,網址可能是 https://example.com/search?q=產品關鍵字,但你不想讓這類搜尋結果頁出現在 Google 或其他搜尋引擎上。你就可以在這些頁面中加上:
<head>
<meta name="robots" content="noindex, follow">
</head>
如此一來,搜尋引擎就算爬了這些頁面,也不會在 SERP(搜尋引擎結果頁)顯示它們。
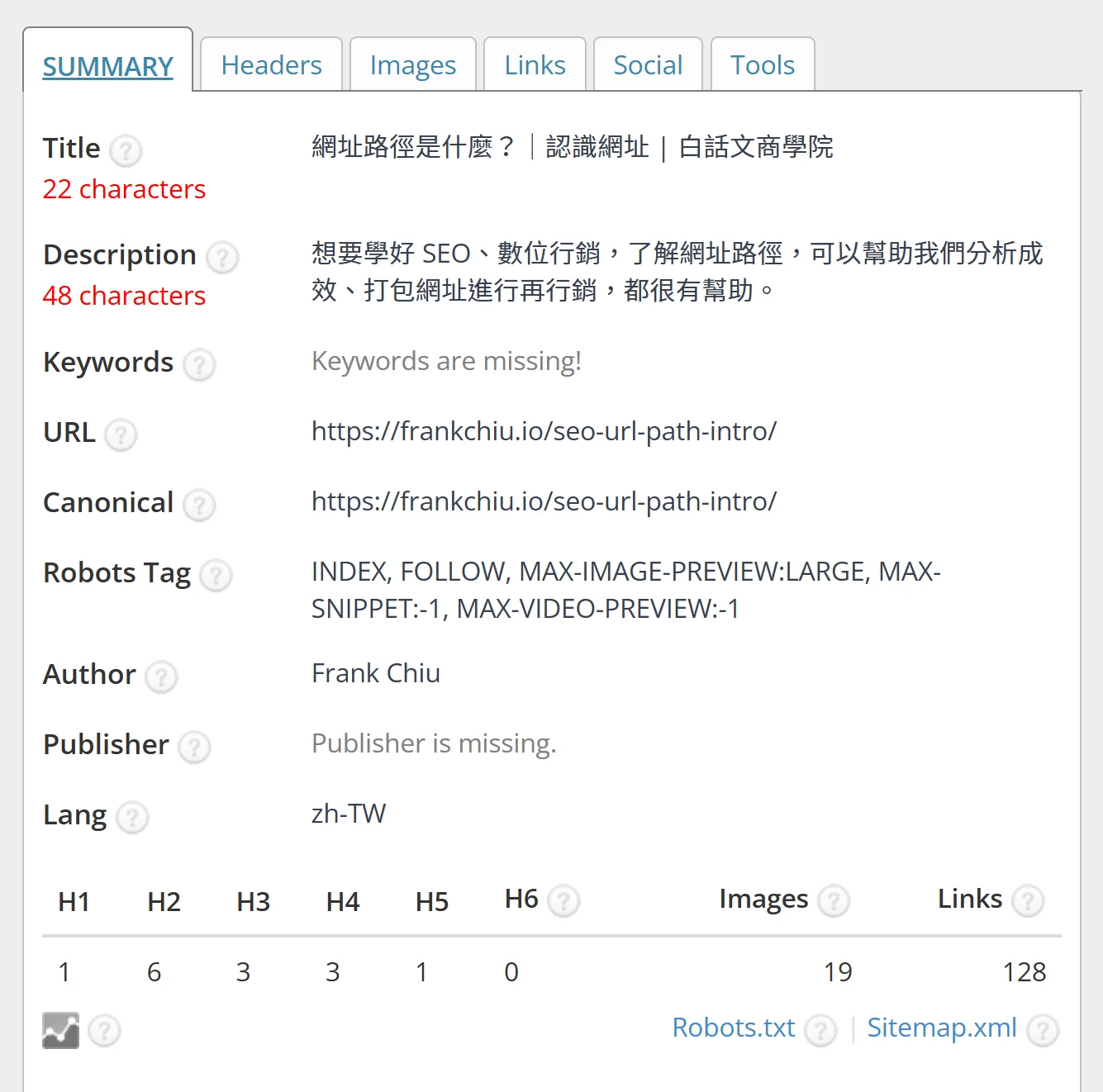
也能利用「SEO META in 1 CLICK」的外掛,來看 Robots Tag 來看 noindex 與否。
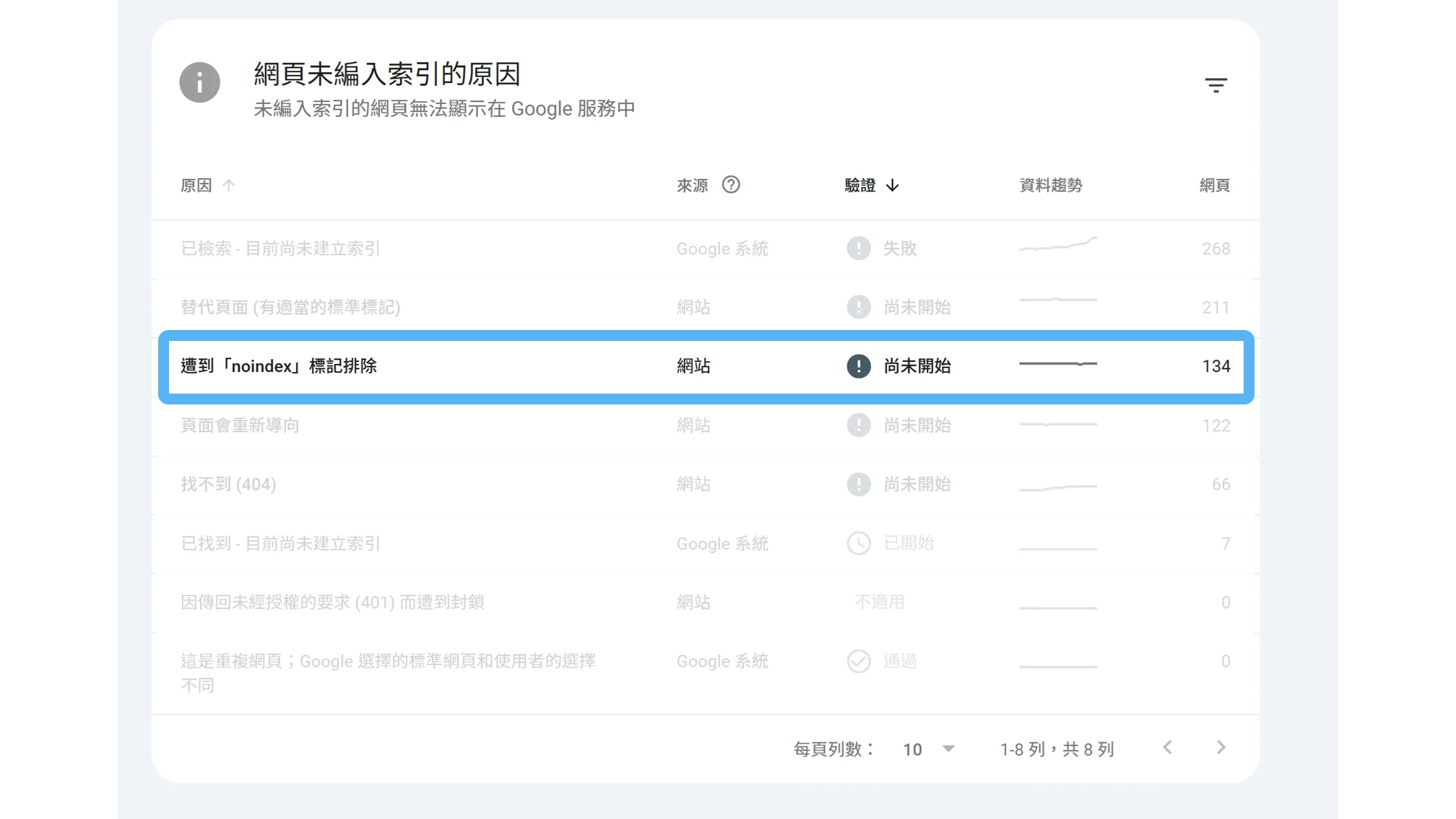
當然,你也可以直接在網頁原始碼,直接搜尋「noindex」。
延伸閱讀:《怎麼看網頁原始碼?SEO 人必會的網頁開發者工具(F12)》
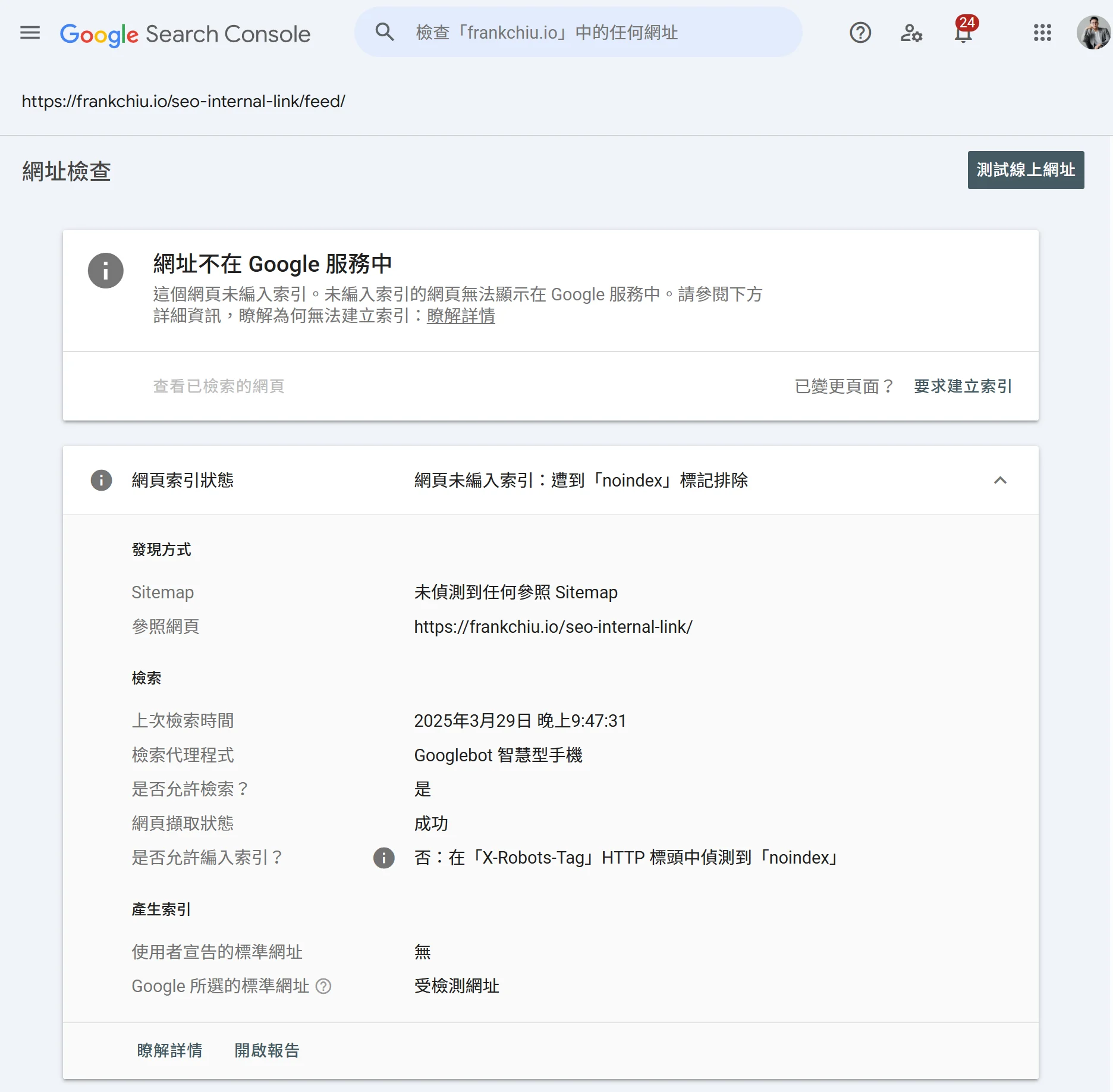
了解上述這麼多內容,最重要的重點是:請確保重要的頁面不要被 noindex。
很多時候因為一些設定、誤會,有些網站會不小心勾選到 noindex,這真的很容易發生。
這也是為什麼我們需要了解 noindex 的原因。
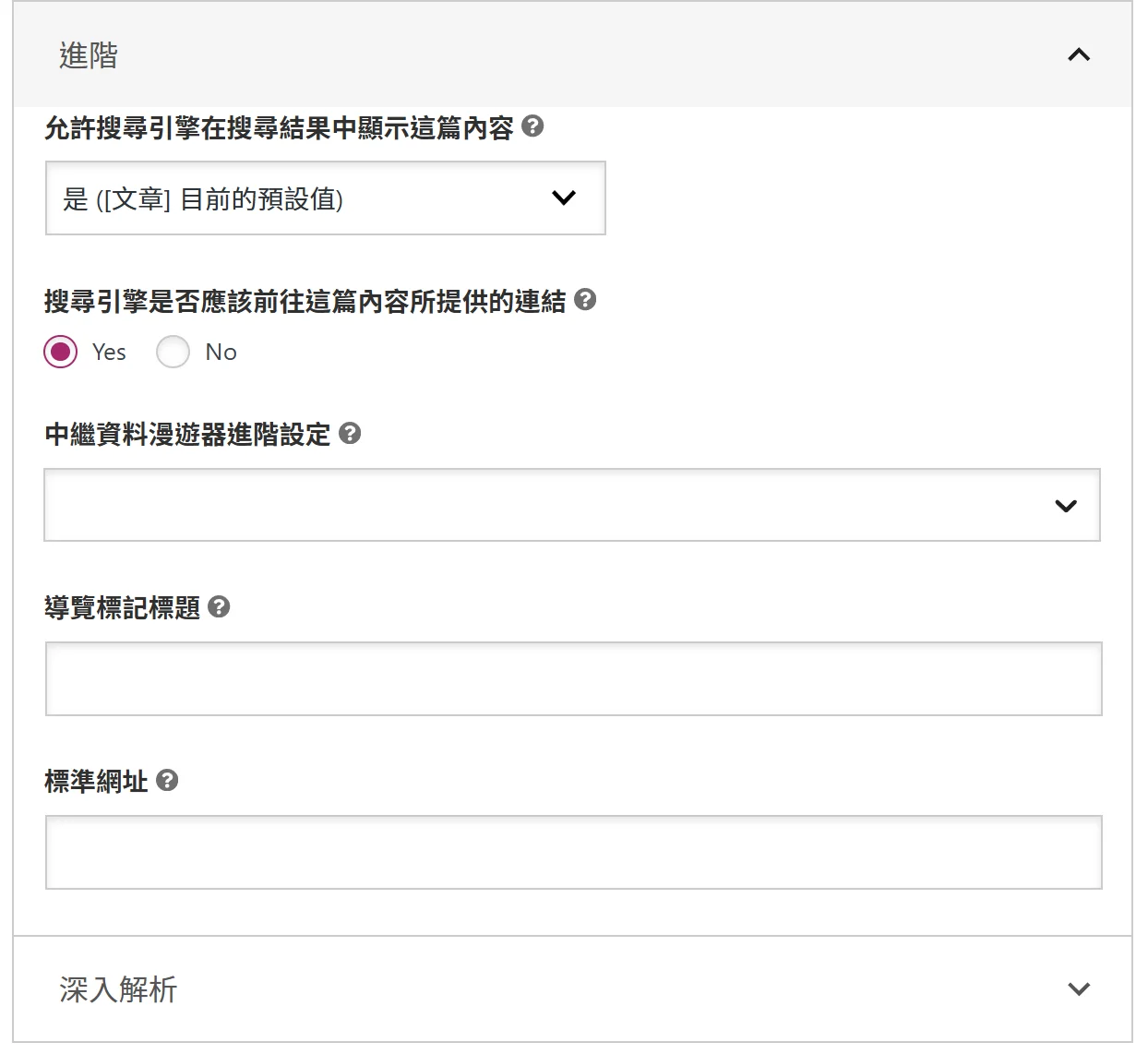
許多 SEO 網站設定,都可以設定是否要 noindex。
像是在 Yoast SEO 中的「允許搜尋引擎在搜尋結果中顯示這篇內容」,就是 noindex 的設定。
如果在 robots.txt 中封鎖了頁面,可能導致爬蟲無法看到你的 noindex,進而無法更新索引狀態,因此「noindex 與 robots.txt 不能一起使用」。
因此如果你不希望某頁面出現在搜尋結果中,最好的做法是「允許爬取,但使用 noindex」。
為了讓 noindex 規則生效,「請勿」使用 robots.txt 檔案封鎖網頁或資源,而是讓檢索器能存取網頁。
如果網頁遭到 robots.txt 檔案封鎖,或是檢索器無法存取網頁,檢索器便無從發現 noindex 規則,使得該網頁仍可能出現在搜尋結果中。比方說,如果有其他網頁連結到該網頁,就可能發生這種情況。
不夠。noindex 並不會阻止爬蟲抓取;若想保護敏感資訊,仍需加上密碼保護或其他權限設定。
通常需要等搜尋引擎再次抓取該頁面並更新索引後,才會陸續移除。
可以參考此文章《不想被索引該怎麼做?不被索引的四個方法|索引技巧》。
一般來說,不建議也不適合將 noindex 和 rel="canonical" 指向不同頁面的指令同時用在同一個頁面上。這會向搜尋引擎發送互相矛盾的訊號。
noindex 的目的: 告訴搜尋引擎「不要將此頁面放入你的索引庫中,不要讓它出現在搜尋結果裡」。rel="canonical" 的目的: 告訴搜尋引擎「這個頁面是另一個頁面(標準版本)的副本或相似版本。請將本頁面所獲得的任何排名訊號(如連結權重)合併到那個標準版本的頁面去」。當你同時使用這兩個指令時:
noindex)rel="canonical")這就像對某人說:「請徹底忘掉這張紙(noindex),但同時也請把我寫在這張紙上的重點轉告給另一個人(rel="canonical")。」
因此建議選擇其中一種就好。
工商時間
如果你想要更系統化、更輕鬆的學好 SEO,推薦你參考我與知識衛星合作的 SEO 線上課程《SEO 排名攻略學:從產業分析到落地實戰,創造翻倍流量》。
這是我的 SEO 集大成之作,讓你從入門到精通,附贈實戰模板跟檢核表,讓你真正學好 SEO。



