
讀懂 token,我們就掌握了生成式 AI 的出入、輸出的核心概念。

你或許沒聽過「Token」,但 Token 正悄悄決定我們跟 AI 對話能說多少話、花多少錢,甚至左右一個專案一天能否跑完所有工作流程。
想像你把長篇小說塞進一台超級翻譯機:書頁會瞬間被裁成一顆顆「字粒」——這些字粒就是 token。
越多 token,機器就要讀得越久、算得越多、收費越高;反之,精準切割、巧妙重組,既能壓低成本,也能讓 AI 模型更容易理解你的內容。
接下來,我們將帶你走進這顆看似微小、卻牽動算力、成本與創意邊界的「字粒宇宙」——讀懂 AI token,我們就掌握了生成式 AI 輸入、輸出與成本控制的核心概念。
Token 就是模型看文字時用的「最小拼圖片」。
Token 不一定等於一個字或一個詞,而是把文字切成常見的字串片段(subword)、單一字元,或特定符號,再把它們變成數字給模型處理。
在 AI 裡,「Token」最常可理解成「詞元」或「符記」,也就是模型處理與產生文字時的基本計算單位——像樂高積木一樣,小到可以自由拼裝,大到能搭出整段文章。模型實際上看到的是這些「積木」的數值表示,再把它們轉成向量做學習與推理。
電影分鏡:把整部片切成鏡頭(Token),導演(模型)讀腳本時就能快速瀏覽、剪輯、重組。
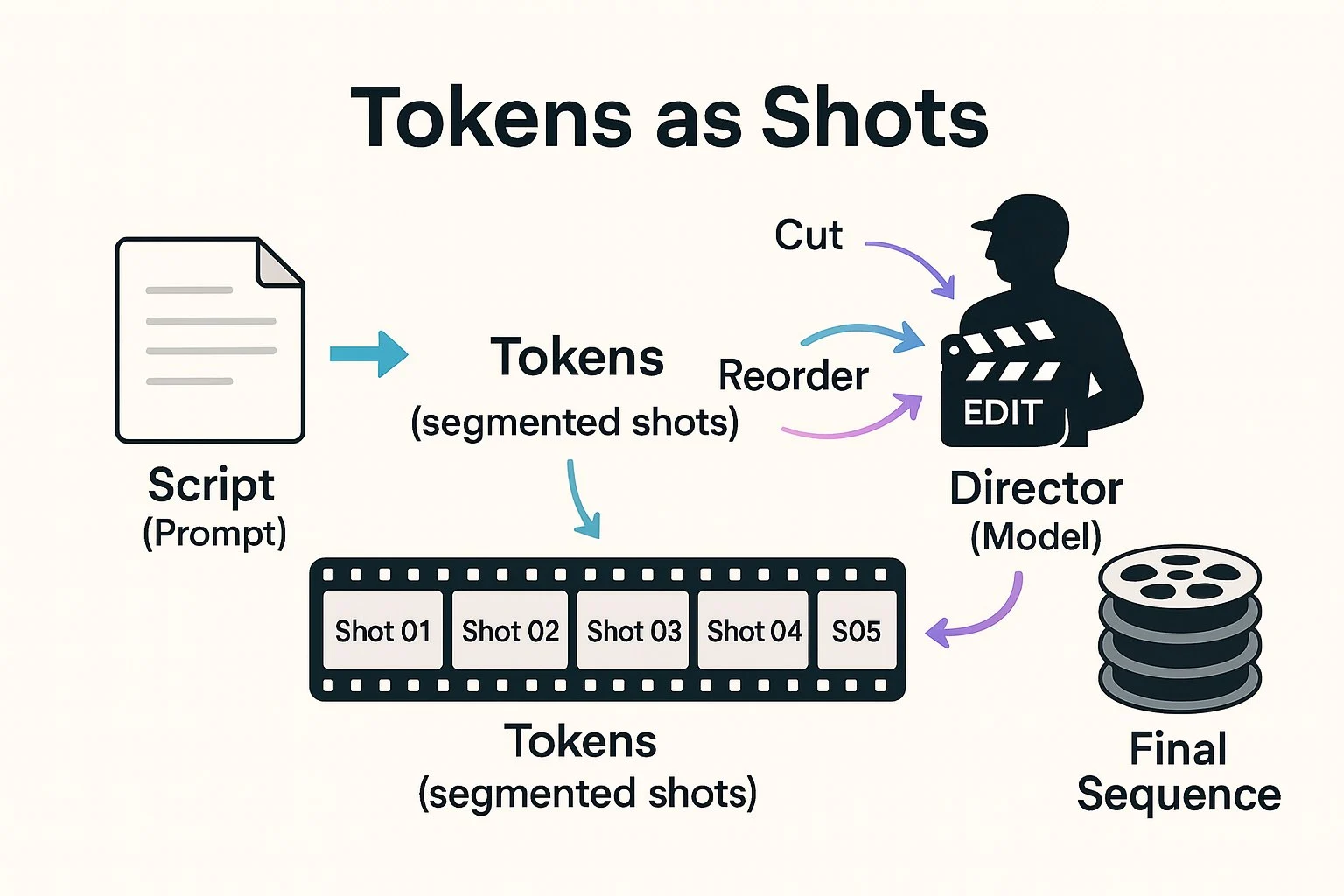
在 AI/大型語言模型的語境中,token 最常譯為「詞元」,也有人譯作「語元」、「符元」、「符記」,或直接保留英文「token」。
如果文章是寫給一般讀者,建議第一次出現時寫成「Token(詞元)」或「token/詞元」,後面再統一使用 token,會比全篇硬翻成中文更自然。
但要注意,如果 token 出現在資訊安全、登入驗證或區塊鏈語境中,意思可能完全不同。登入驗證的 token 常譯為「權杖」;加密貨幣裡的 token 則常譯為「代幣」。本文討論的是 AI 與大型語言模型中的 token。
英文裡,常見經驗值可以先抓 1 token 約等於 4 個字元、或約 3/4 個英文單字。
短詞如 “chat” 可能是一顆 token;較長單字則可能被切成多段。
中文沒有穩定的「每個字固定等於多少 token」公式。不同模型可能使用 BPE、SentencePiece 或其他近似子詞切分方法,實際比例會受標點、空格、中英混排、專有名詞與上下文影響,所以估算前最好用官方 tokenizer 或 count tokens 工具實測。
外部參考:OpenAI Counting tokens、OpenAI tiktoken 教學
對多數人來說,理解 Token 不是為了研究 AI 技術、成為 AI 工程師,而是為了知道 AI 到底怎麼「讀懂」我們輸入的內容。
Token 會影響 AI 一次能看多少文字、回答可以寫多長,也會影響使用速度和費用。
當你知道 Token 是 AI 處理文字的基本單位後,就比較容易理解,為什麼有些問題明明很長,AI 卻抓不到重點。很多時候,不是 AI 突然變笨,而是輸入內容太亂、太長,或重要資訊被埋在後面。
對一般使用者來說,懂 Token 最大的好處,就是更知道怎麼把話說清楚。你會開始習慣把需求講短一點、重點放前面,讓 AI 更快理解,也讓回覆更接近你真正想要的結果。
這件事看起來很次要,但實際上很重要。
無論你是拿 AI 來寫文章、整理資料、做簡報,還是處理工作流程,理解 Token 都能幫助你更省時間、更省成本,也更容易把資訊灌入 AI。
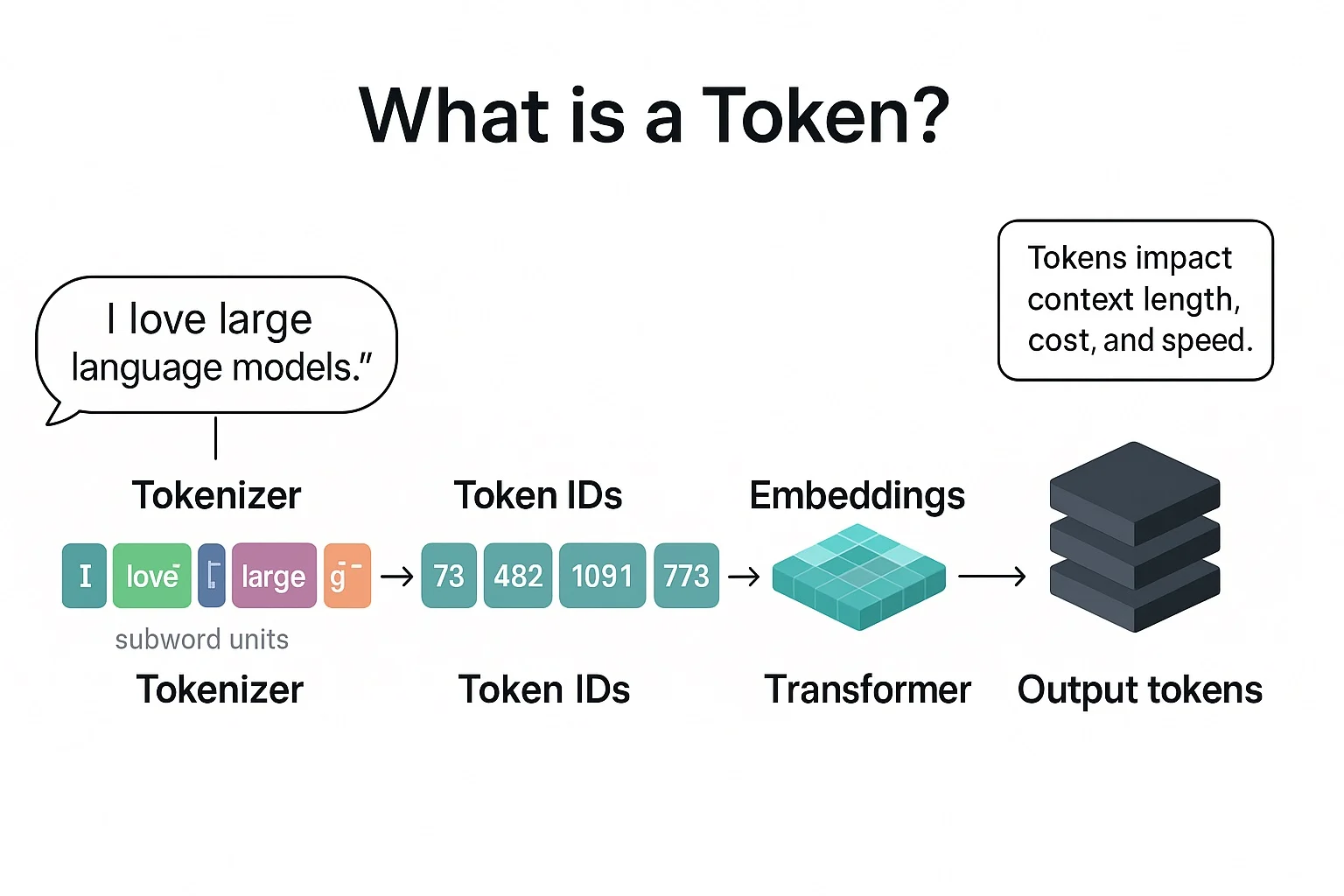
Token 的計算方式,簡單說就是:先把文字切成 token,再把 token 數量加總。
但真正麻煩的地方在於,token 不是用「中文字數」或「英文單字數」直接換算,而是由模型使用的 tokenizer 依照自己的切分規則來決定。也就是說,同一句話,換一個模型、換一種語言、換一種標點與空格,最後算出來的 token 數都可能不同。
如果一篇文章是一盒拼圖,tokenizer 就像是把拼圖拆開的人;模型不是直接看整張圖,而是看一片片拼圖,再判斷下一片應該接在哪裡。
你輸入一句「AI token 是什麼?」時,模型不一定會把它看成 5 個中文字加幾個英文字母,而是可能切成「AI」、「 token」、「 是」、「什麼」、「?」這類片段。實際切法會依模型與 tokenizer 而變。
所以,token 計算不是在數「人眼看到幾個字」,而是在數「模型實際收到幾個文字片段」。
如果只看一次文字對話,最簡單可以先這樣理解:
總 token 數 = input tokens + output tokens
例如你送出一段 800 tokens 的文章,請模型整理成 300 tokens 的摘要,那這次請求的基本消耗就可以先粗略理解成 1,100 tokens。
但這只是最乾淨的情況。實務上如果加上長對話、工具呼叫、圖片、檔案、快取與 reasoning model,token 的組成會更複雜。
很多人以為 token 只會計算自己輸入的問題,其實不是。
在實際 API 或 AI 工具裡,模型看到的內容可能包含:
所以你在畫面上看到的文字,通常只是模型實際收到內容的一部分。對一般使用者來說,最重要的觀念是:只要內容被送進模型參考,就可能消耗 input tokens。
中文 token 沒有一個永遠正確的公式。
有時一個中文字接近一個 token,有時標點、英文、數字、空格、專有名詞或 emoji 會讓 token 數變多。尤其是中英混排、程式碼、表格、網址與型號規格,通常比一般段落文字更難估。
如果只是寫文章或做內容規劃,可以先用這個方式抓大方向:
更穩的做法是:先拿文章中的 300–500 字去測 token,再算出「每 100 字大約消耗多少 token」,最後再外推整篇文章。這會比直接用「中文字數 ÷ 某個固定數字」可靠得多。
如果你是用 OpenAI API 或其他 LLM API,回傳結果裡通常會看到 usage 類欄位。
在新版 Responses API 裡,常見欄位會像這樣:
input_tokens:這次請求送進模型的 token 數。output_tokens:模型這次產生的 token 數。total_tokens:input tokens 與 output tokens 的加總。cached_tokens:命中快取的輸入 token,通常代表重複上下文被系統辨識出來,實際費率可能不同。reasoning_tokens:某些推理模型內部思考使用的 token,不一定會直接顯示在最後答案裡。這也是為什麼你明明只看到一小段回答,後台 token 使用量卻可能比想像中高。因為模型可能讀了很長的上下文,也可能在內部做了額外推理。
AI 對話不是每一輪都完全從零開始。
為了讓模型記得前面談過什麼,系統通常會把部分歷史對話、摘要或狀態一起送進模型。這些內容會佔用 context window,也可能計入 input tokens。
這也是為什麼長對話到後面容易出現三種狀況:
如果你在做工作流程、客服機器人、長文件問答或 RAG 系統,不能只看單次提問的 token,而要看「每一輪實際送進模型的完整內容」。
Token 不只存在於一般文字。
當你把圖片丟給支援視覺的模型時,系統通常會依圖片尺寸、細節設定與模型規則,把圖片轉成可計算的 token 或等價單位。圖片越大、細節越高,通常消耗越多。
當你上傳 PDF、Word、表格或網頁內容時,系統也可能先抽取文字、切分段落,再把相關片段送進模型。這些被送進去的內容,同樣可能算進 input tokens。
如果使用 web search、file search、code interpreter、function calling 等工具,工具說明、工具參數、搜尋結果與中間輸出也可能增加 token 消耗。這就是為什麼「同樣一句問題」,開工具和不開工具,成本可能不同。
如果只是聊天或寫文章,不需要每次都精算 token,只要知道「越長越貴、越複雜越不穩」就夠了。
但如果你要估 API 成本、規劃產品功能、切 chunk、做 RAG、設計客服機器人,建議用下面流程:
簡單來說,估算靠樣本,精算靠工具,結算看 API 回傳的 usage。
Token 計算不是單純數字數,而是在看「模型實際收到多少片文字拼圖,又產生多少片新的拼圖」。
對一般人來說,理解這件事可以幫你寫出更精準的 prompt;對開發者、SEO 人員與內容團隊來說,token 計算則會直接影響成本、速度、上下文設計與內容切分策略。
外部參考:OpenAI Counting tokens、OpenAI tiktoken 教學、OpenAI Reasoning models
多數雲端 API 會把 input tokens 和 output tokens 當成主要計價單位:你送 100 token 的問題,模型回 300 token,總消耗就是 400 token。
但實際費用不只受輸入與輸出長度影響,還可能和 cached input、長上下文、batch / priority / flex 等服務模式,以及 web search、container 或其他工具功能有關。
換句話說,token 不只是技術名詞,也是一種成本語言。當你在做大量內容生成、文件摘要、客服機器人、資料抽取或自動化流程時,token 用量會直接影響每月帳單。
OpenAI 的價格頁會依模型與服務模式更新;如果文章重點是概念教學,比起把每個模型的單價寫死,更建議理解「不同模型有不同 input / cached input / output 定價」,並把最新數字交給官方 pricing 頁維護。
比較耐久的理解方式是:
外部參考:OpenAI API Pricing、OpenAI Models

註:上圖可作為「不同模型、不同欄位會有不同 token 定價」的示意;實際數字請以官方價格頁為準。
關於更多不同模型的 Token 費用,可以參考:
Helicone – LLM API Pricing Calculator(helicone.ai/llm-cost)

先感覺一下「尺度感」:1 Token 大概是多少文字?
對中文、日文與中英混排內容來說,token 長度變動通常比較大。若你要估價、切 chunk、做 RAG 或規劃上下文視窗,最穩妥的方法仍是拿一小段代表性文本先實測,再按比例推估整份文件。
簡易做法:
不同模型的 context window 差異很大,從數十萬到百萬級 token 都可能出現;不能把某一代模型簡化成固定一個數字。
如果只是建立尺度感,可以先拿 256K token 當示例 來想像:
英文
中文
延伸閱讀:《ChatGPT 怎麼用?ChatGPT 教學:帳號註冊、22 種技巧》
在生成式搜尋時代,內容常常會先被切成片段,再進入檢索、排序、摘要與生成流程。理解 token,有助於你掌握內容的切分成本、摘要長度預算與大模型讀取方式。
但 token 並非是唯一決定因素。
內容能否被看見、被引用、被摘要,通常還和資訊品質、原創性、可抓取性、結構清晰度、實體訊號與來源可信度有關;也就是 GEO(Generative Engine Optimization),但它不是唯一或官方標準術語。
外部參考:Google Search Central:AI features and your website
延伸閱讀:《GEO 是什麼?與 SEO 有何差異?GEO 生意機會全面解析》
在生成式搜尋時代,SEO 不只追關鍵字,也不只是「管理 token」。更務實的做法,是同時管理內容品質、資訊結構、可擷取性與成本意識;token 是其中一層,但不是全部。
在大型語言模型裡,token 就是模型讀取與產生文字時的基本單位。它可能是一個字母、一段字串、一部分單字、標點符號,或某些情況下的一整個詞。
模型會先把輸入切成一串 token,再進行運算,最後依序產生新的 token 作為輸出。
簡單來說,token 收費本質上是在反映雲端推理與基礎設施成本;用得越多、佔用的計算資源越多,費用通常就越高。
ChatGPT 的 token 不是用「字數」直接計算,而是由模型的 tokenizer 先把輸入內容切成一段段 token,再統計模型實際讀進去與產生出來的數量。
一般可以先理解成:總 token 數 = input tokens + output tokens。input tokens 包含你的問題、上下文、系統指令、歷史對話、檔案內容或工具結果;output tokens 則是模型產生的回答,以及某些推理模型內部使用的 reasoning tokens。
在舊版 Chat Completions API,你常會看到 prompt_tokens、completion_tokens 與 total_tokens;在新版 Responses API,則常見 input_tokens、output_tokens 與 total_tokens。名稱不同,但核心概念一樣:統計模型讀了多少、寫了多少、總共消耗多少。
如果只是抓大概,英文可以用 1 token 約等於 4 個字元粗估;中文、中英混排、表格、網址、程式碼與專有名詞則建議用 tokenizer 或官方 token counting 工具實測,因為誤差會比較大。
英文的經驗值通常抓 1 token ≈ 4 字元,或約 3/4 個英文單字。
中文沒有固定常數。若只是快速抓尺度感,可以先理解成「中文通常比英文更耗 token」,但真正估算時,還是以模型實測最準。
Token 不是算力,而是模型處理語言時的基本單位,可能是一個字、詞的一部分、整個詞,或標點符號。
算力則是模型完成訓練或推理時消耗的計算資源,例如 GPU 性能、記憶體頻寬、運算量與延遲。兩者有關,但不是同一件事:token 數量越多,通常代表要處理的內容越長,推理時間與成本往往也會增加;但真正影響速度、價格與表現的,還有模型規模、架構設計、量化方式、批次大小與硬體效率。
不一定。
Token 太多會增加成本,也可能讓重點被稀釋;但 token 太少,模型可能拿不到足夠背景資訊,反而回答得更籠統、更容易誤解需求。
比較好的方向不是一味壓低 token,而是提高 token 的資訊密度:刪掉寒暄、重複與無關背景,把任務、條件、格式、範例和限制寫清楚。
可以從三個方向下手。
第一,減少無效輸入,把長篇背景整理成重點摘要,再交給模型處理。第二,控制輸出長度,例如指定「請用 5 點回答」或「摘要在 300 字內」。第三,對重複使用的上下文、系統提示與知識庫內容,評估是否能透過快取、摘要、chunk 切分或 RAG 檢索來降低每次送進模型的內容量。
但不要為了省 token 把重要條件刪掉。省下來的 token 如果讓模型誤解任務,最後反而會增加重跑、修正與人工檢查成本。
延伸閱讀:在加密貨幣的語境裡,token 通常被譯為「代幣」,和這裡談的 AI token 是兩回事;想分清楚,可以參考《虛擬貨幣是什麼?》。



