
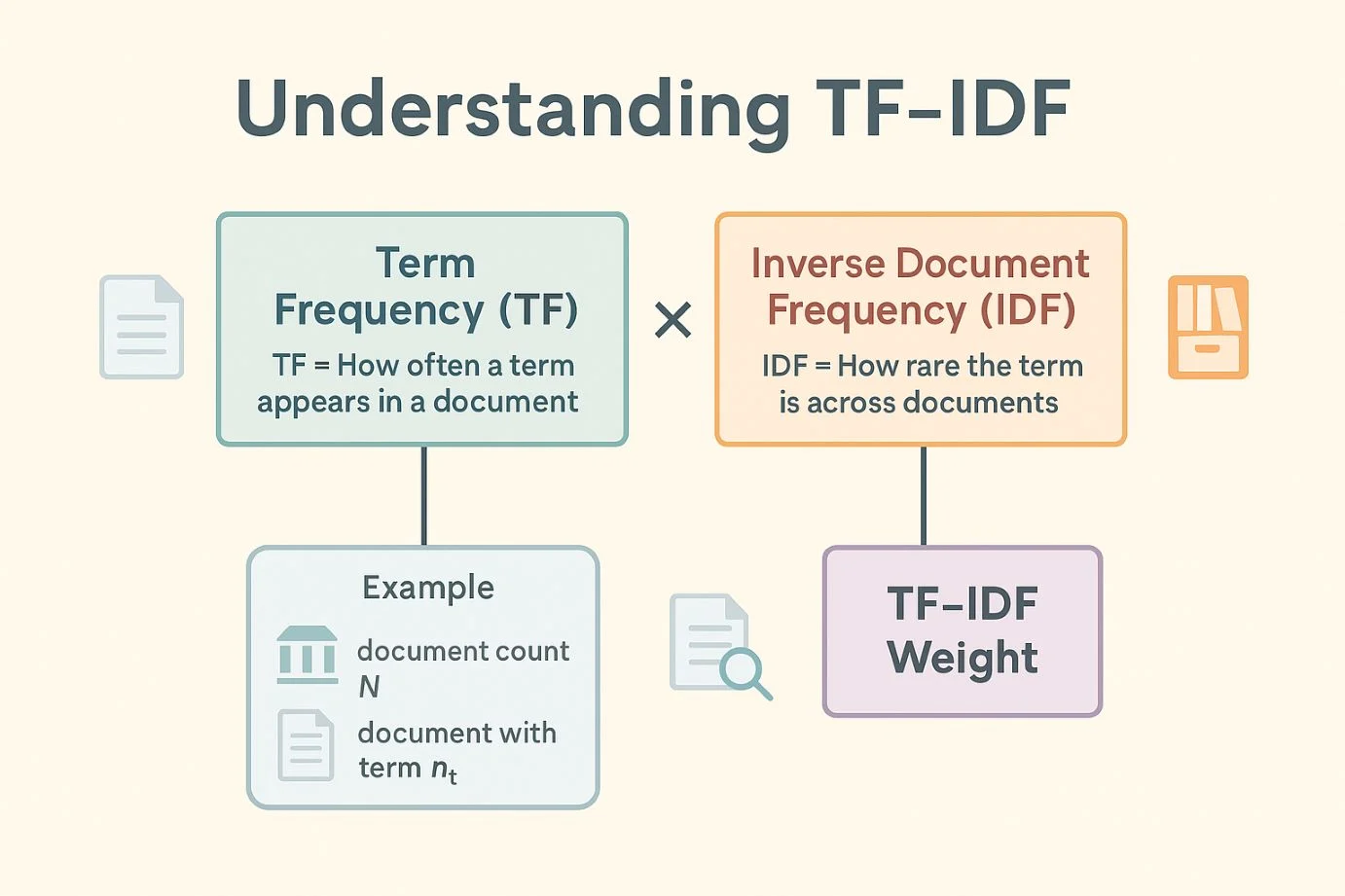
TF-IDF 同時看一個詞在單篇文章裡出現的頻率,和它在整個文件庫裡的稀有程度,藉此為每個詞加上分數。

當我們寫報告、做資料分析,還是經營部落格,我們都會想要「抓出文章重點關鍵詞」的需求,來知道哪些字詞是最重要的。而 TF-IDF 提供了一條捷徑:把詞頻(Term Frequency)與稀有度(Inverse Document Frequency)結合,就能快速計算出詞的重要性。
TF-IDF 同時看一個詞在單篇文章裡出現的頻率,和它在整個文件庫裡的稀有程度,藉此為每個詞加上分數。
透過了解 TF-IDF 能幫助我們快速篩出關鍵詞、優化站內搜尋,或替 SEO 內容做詞彙診斷,是入門資訊檢索與 NLP 的基礎工具之一。
TF-IDF(Term Frequency – Inverse Document Frequency,詞頻-逆文件頻率)是一種經典的統計權重,用來衡量「某個詞彙對單一文件的重要程度」,同時考慮這個詞在整個語料庫(corpus)裡的普遍程度。
TF-IDF 長期用於資訊檢索、文字探勘、推薦系統與各式 NLP 管線。TF-IDF 至今仍是 2025 年許多搜尋與排序模型的基礎特徵之一。
只記住這兩句,你就已經抓到 TF-IDF 的核心概念了。
想像你擔任「圖書館小偵探」,任務是幫老師找出每本故事書最特別的詞。
你有兩把量尺:
當你把兩把量尺相乘,就得到一個「亮度值」:
這個亮度值就是 TF-IDF。它告訴電腦:「哪個詞最值得被注意?」
簡單舉例
「獨角獸」:在《魔法森林》這本書出現 5 次,但全圖書館只有 2 本提到它。→ 亮度高,代表這本書很可能在講魔法生物。
「的」:在每本書都出現上百次。→ 亮度低,因為它對分辨故事沒幫助。
IDF 的重點在於:分析整個語料庫(corpus)中特定詞彙稀不稀有,那我們要怎麼挑選語料庫?
挑語料庫就三件事:想清楚目標 → 收集相關文件 → 定期更新。
1. 先想清楚你要解決什麼問題
2. 把真正相關的文件放在一起,其他一律不要
3. 跟著內容變動頻率去重建語料庫
小結:語料庫只要剛好覆蓋你的任務範圍,又不把無關內容塞進來,就能讓 TF-IDF 真正反映你想比較的世界。
在 Google 與 Bing 已用上大型語言模型的 2025 年,TF-IDF 仍是 SEO 可以參考的「內容診斷尺」,原因主要有三個層面:
現代搜尋通常將「稀疏關鍵字分數」(如 BM25)與「稠密語意向量」混合排序。
以 2025 年的實務來說:
BM25 屬於機率相關度模型——汲取 TF-IDF 的 TF/IDF 思想並加入文件長度校正,因此成為許多「第一階粗排」的標準做法。
延伸閱讀:《BM25 介紹:BM25 如何決定你餵給 LLM 的素材?》
在寫稿或改稿前先對自家頁面與 SERP 前幾名做 TF-IDF 比對,找出用詞過少或過度重複的項目,再自然補齊或刪減,以免關鍵字填塞或語意不足。
這也是某種「更量化的搜尋意圖分析」。
新版 Surfer SEO、Ryte、SEMrush 也把 TF-IDF 報表做成「缺詞清單」;實測顯示補完這些詞可提升內容相關度,間接帶動排名。
進階做法還會把 TF-IDF 分數高的詞拿來當錨文字(anchor text),強化頁面之間的語意連結,避免一律使用「點這裡」這種無意義鏈結詞。
延伸閱讀:《拆解「搜尋意圖」:何謂搜尋意圖?SEO 高排名的核心關鍵》
Google 的「Helpful Content」與 RankBrain/AI 檢索,評估的不只是一兩個數值,而是整體內容品質、使用者滿意度與頁面權威。TF-IDF 只是最快速、最可解釋的量尺——用來發現語意缺口與避免關鍵字迷信;但 TF-IDF 並是排名保證。
TF-IDF 與 SEO 的關聯在於「用它做內容體檢,讓文章在競爭激烈的 SERP 中語意更完整、關鍵字更自然」,而搜尋引擎也仍在背後用衍生演算法(BM25 等)參與排名計算,所以依然值得你了解。
步驟:
備註:在分子、分母各加 1(平滑)可避免 nₜ = 0 時除以 0,並抑制極端稀有詞帶來的誤差。
換句話說,愈少文件提到的詞,IDF 值就愈大,代表它較稀有。
最後將 TF 與 IDF 相乘:TF-IDF = TF × IDF
若某詞在文章裡常出現(TF 高),且在整個語料中很少見(IDF 高),便擁有最高權重。
你的原文〈個人品牌:從零開始的行銷思維〉目前停留在 Google 第 2 頁。根據 SurferSEO 針對 1 百萬個 SERP 列表的研究,內容得分與排名仍然保持顯著相關(Spearman ρ≈0.28)。因此,我們鎖定「讓文章內容在語義完整度上超車競品」(對標網址)這個目標,採用 TF-IDF 差距分析作為優化起點。
收斂查詢意圖:先用 Keyword Planner 與 Surfer 的 Keyword Ideas 功能,把「個人品牌」「個人品牌經營」「personal branding strategy」等月搜尋量 ≥ 300 的關鍵字彙整成清單。
抓取 SERP 前 15 名:對每一個關鍵字以無痕模式擷取自然結果,把正文 HTML 下載並清洗導航、廣告與評論區。這 40–60 篇文章就是之後計算 IDF 的母體。Surfer 官方的競品分析流程也是以相同步驟建立 top-k 語料庫。
使用 jieba 斷詞(中文)與 spaCy(英文),刪除停用字與標點;
對這批文件計 idf(t)=log(N/(1+df(t)));
為確保可比性,所有文章(競品與你的原文)都用「對數縮放 TF」並做字數正規化,避免長文先天佔便宜。
把你的文章與競品的 TF-IDF 向量疊在一起,對每個詞計算「你 ÷ 競品平均」。
若比值 < 0.5,標記為缺詞;
若比值 > 2 且高過競品 75 百分位,標記為可能過度。
工具層面可直接用 Surfer 的 Content Gap 介面,或手動用 scikit-learn 寫腳本;Surfer 會同步顯示內容得分,方便即時驗證。
缺詞補強
過度詞降噪
結構與標記
修改完畢後透過 Search Console「檢查網址」功能重新提交索引,並在接下來兩週觀察流量變化。



