
本文會帶你理解:LLM 是什麼、和 ChatGPT 差在哪、基本原理是什麼、可以拿來做什麼、有哪些限制,以及新手該怎麼開始學。

LLM 是 Large Language Model 的縮寫,中文通常翻成「大型語言模型」。
你現在常聽到的 ChatGPT、Claude、Gemini、Llama,背後都和大型語言模型有關。它們可以回答問題、摘要文章、翻譯、寫程式、整理資料、產生企劃,也能協助我們學習一個完全陌生的主題。
如果你是第一次接觸 AI,我會建議你先記住一句話:LLM 是一種很會處理語言的 AI 模型,但它不是搜尋引擎,也不是保證正確的資料庫。
它可以大幅提升工作與學習效率,但如果你把它當成權威本身,就很容易踩到錯誤資訊、幻覺、資料外洩、著作權與過度依賴的坑。
本文會帶你理解:LLM 是什麼、和 ChatGPT 差在哪、基本原理是什麼、可以拿來做什麼、有哪些限制,以及新手該怎麼開始學。
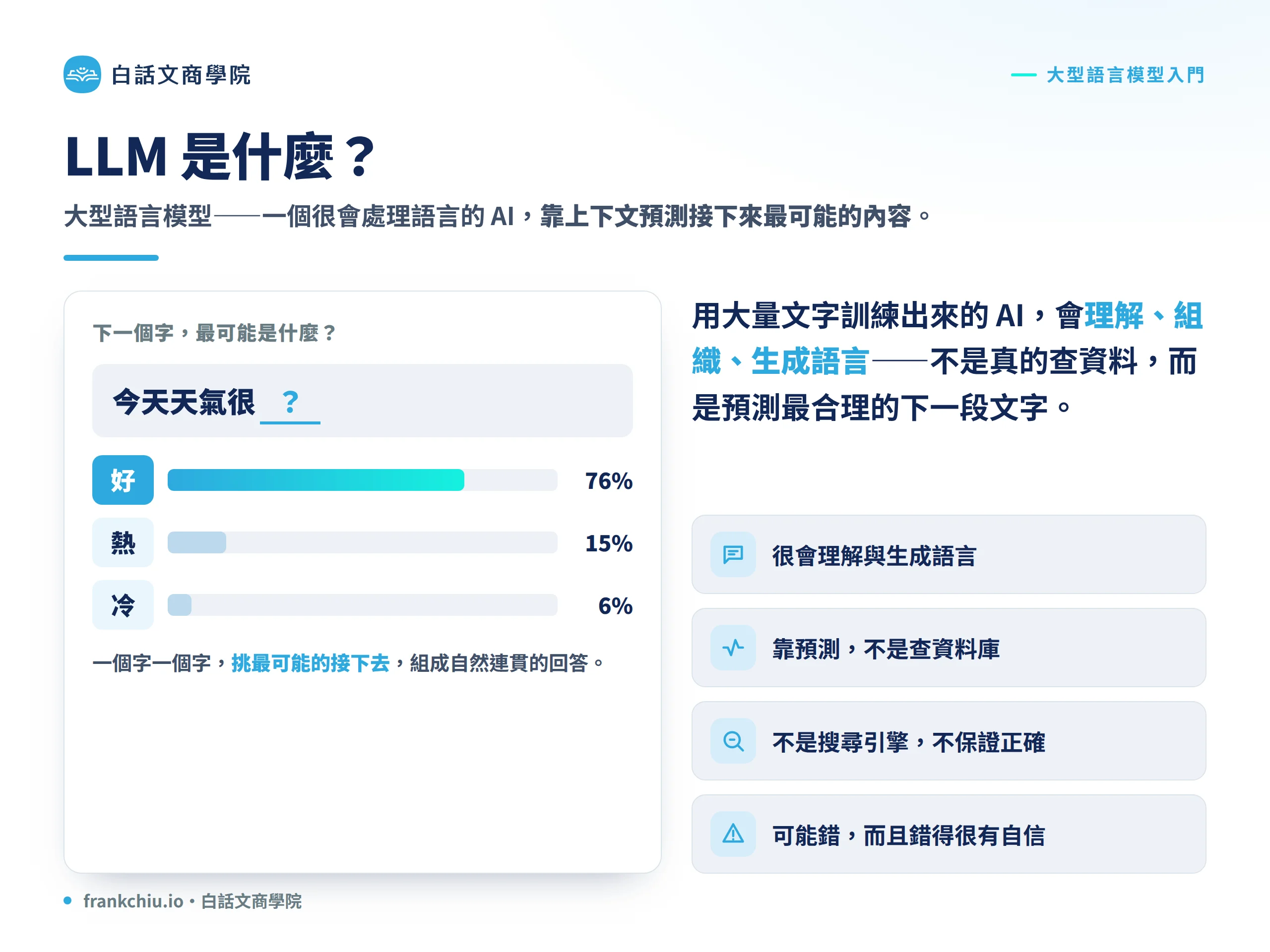
LLM,全名是 Large Language Model,大型語言模型,是一種透過大量文字與資料訓練出來的 AI 模型,主要用來理解、預測、生成和組織語言內容。
你可以把它想成一個非常大型的「語言預測系統」。當你輸入一句話、問題、文章或指令後,它會根據上下文判斷接下來最可能出現什麼內容,然後生成一段看起來自然、連貫、有邏輯的回答。
但這裡有一個很重要的觀念:LLM 不是像人類一樣真正經歷世界,也不是像資料庫一樣儲存每一筆可查詢的真實資料。
它擅長的是語言模式、文字組織、語意推理和內容生成。因此它可以很會寫、很會整理、很會解釋,但也可能講錯,而且有時候會錯得很有自信。
想看比較正式的入門說明,可以參考 Google 的 Large Language Models 課程,以及 IBM 對 大型語言模型 的介紹。
很多人會把 LLM 和 ChatGPT 混在一起講,但兩者其實不是同一件事。
ChatGPT 是 OpenAI 推出的 AI 對話產品,而 LLM 是背後使用的模型類型。簡單說,LLM 比較像引擎,ChatGPT 比較像一台車;你平常操作的是車,但真正提供動力的是引擎。
同樣道理,Claude、Gemini、Copilot、Perplexity、Llama 這些名稱,有些是產品,有些是模型,有些是平台,有些是開源或開放權重模型。新手剛開始不用全部記起來,但要知道「產品名稱」和「模型類型」不能完全畫上等號。
LLM 的技術細節很深,但新手不需要一開始就學數學公式。先理解幾個核心概念,就能避免大部分誤解。
LLM 不是用人類的方式逐字讀文章,而是會先把文字切成 token。token 可以是一個字、一段字、一個詞,或英文單字的一部分。
這也代表你丟給模型的內容越長,它需要處理的 token 越多,可能就會影響速度、成本和能不能完整讀完。
Context Window 可以想成模型的「桌面大小」。你把文章、問題、指令、資料都放到這張桌面上,它才能根據這些內容回答。
如果資料太多、超過模型能處理的範圍,它可能會漏掉前面的資訊,或只抓到局部內容。所以長文件處理不是單純「全部丟進去」就好,常常需要分段、摘要、建立結構,或搭配檢索工具。
現在大多數主流 LLM 都和 Transformer 架構有關。Transformer 讓模型能更有效地判斷句子中不同詞語、段落之間的關係。
例如你問:「蘋果去年營收如何?」模型需要判斷你說的「蘋果」是 Apple 公司,而不是水果。這種根據上下文判斷語意關係的能力,就是 LLM 很重要的基礎。
Transformer 的代表性論文是 2017 年的 Attention Is All You Need,如果你未來想往技術方向深入,可以從這篇開始延伸。

LLM 最實用的地方,是它可以把很多原本需要花時間思考、整理、改寫的工作變快。
不過它比較像是高效率助理,不是最終負責人。你可以讓它幫你起草、整理、發想、解釋,但重要內容還是要自己判斷。
你可以把文章、會議紀錄、訪談逐字稿、研究資料丟給 LLM,請它整理成重點摘要、待辦事項、表格或簡報大綱。
指令參考:
LLM 很適合拿來處理初稿。像是 email、社群貼文、文章大綱、企劃書、產品文案、履歷、自我介紹,都可以先請它產出版本,再由你修改。
指令參考:
LLM 不只可以翻譯,還可以依照不同讀者調整語氣。例如把英文技術文件改成台灣讀者比較容易理解的繁體中文。
指令參考:
LLM 很適合當作學習輔助工具。當你剛接觸一個新領域,可以請它先解釋名詞、整理架構、設計學習路線,甚至出題測驗你。
指令參考:
LLM 可以協助寫程式、解釋程式碼、找 bug、產生測試案例。對初學者來說,它也能把看不懂的程式碼逐行解釋。
但程式碼仍然需要測試,尤其是牽涉資安、付款、資料庫、權限、個資時,不建議直接複製貼上就上線。
企業常見的用法,是把 LLM 和內部文件、FAQ、產品說明、客服紀錄結合,讓它根據公司資料回答問題。
這類做法通常會用到 RAG,也就是 Retrieval-Augmented Generation,讓模型先檢索資料,再根據資料生成回答。Anthropic 的 Glossary 對 RAG 有簡潔定義。

LLM 很強,但它不是萬能。新手最需要小心的,不是它不會,而是它「看起來很會」。
幻覺指的是模型產生不正確、但看起來很合理的內容。例如編造不存在的論文、錯誤的法條、假的統計數字,或把不同事件混在一起。
如果你要處理醫療、法律、投資、學術、新聞、價格、政策、模型版本等資訊,一定要回到官方來源或權威資料查證。
有些 AI 工具可以上網搜尋,有些不行;有些有搜尋功能,但搜尋結果也可能不完整。
所以當你問「最新模型排名」、「現在價格」、「今年法規」、「今天新聞」這類問題時,不能只看模型回答,要確認它是否提供來源、來源日期是否夠新,以及是否來自官方或可靠機構。
不要隨便把公司機密、客戶個資、合約、財務資料、醫療資料、未公開企劃丟進不確定的 AI 工具。
如果公司要導入 LLM,應該先確認資料保留政策、是否會用輸入內容訓練模型、權限控管、日誌紀錄、資料所在地,以及是否符合內部資安規範。
LLM 可以幫你整理法律條文、醫療資訊或投資報告,但不能替你做最後判斷。
越是錯誤成本高的任務,越需要人工審核。可以把 LLM 當成研究助理,但不要把它當成律師、醫師、會計師、投資顧問或主管本人。
| 工具 | 主要功能 | 適合任務 | 要注意什麼 |
|---|---|---|---|
| LLM | 生成、整理、解釋語言內容 | 寫作、摘要、學習、發想、程式輔助 | 可能幻覺,需要查證 |
| 搜尋引擎 | 找到網頁與資料來源 | 查最新消息、官方資訊、不同觀點 | 需要自己判斷來源品質 |
| 資料庫 | 儲存與查詢結構化資料 | 庫存、訂單、會員、財務紀錄 | 不會自動理解複雜語意 |
如果你要「理解一個主題」,LLM 很方便。如果你要「確認最新事實」,搜尋引擎和官方來源很重要。如果你要「查一筆精確資料」,資料庫才是正確工具。

如果你主要使用繁體中文,建議特別注意三件事。
第一,模型是否真的熟悉台灣語境。不是所有中文模型都能自然處理繁體中文、台灣用語、在地法律、教育制度、商業習慣和文化脈絡。
第二,避免中國用語或不符合台灣情境的翻譯。像是「質量、視頻、信息、軟體著作權、增值稅」這類詞,在不同地區可能有不同用法,正式內容最好人工檢查一次。
第三,公部門、教育機構、金融、醫療、法律等場景要更謹慎。台灣國科會網站有整理行政院及所屬機關使用生成式 AI 的相關指引與 FAQ,可作為理解公部門使用原則的參考:生成式 AI 參考指引 FAQ。
如果你完全沒有基礎,不需要一開始就研究模型架構或訓練方法。比較好的方式,是先從實際任務開始。
先理解 LLM、ChatGPT、生成式 AI、token、context window、幻覺這幾個詞。這些概念懂了,就能避免很多錯誤期待。
先拿不敏感的資料練習,例如摘要公開文章、改寫自己的筆記、翻譯產品介紹、產生文章大綱、解釋不懂的概念。
不用迷信神奇 prompt。新手只要記住幾個元素就很好用:背景、目標、讀者、格式、限制、範例。
例如:
好的指令不一定要很長,重點是讓模型知道你要解決什麼問題、回答給誰看,以及結果應該長什麼樣子。
當回答涉及人名、日期、價格、統計數字、研究結果、法規或最新消息時,不要直接複製使用。
你可以要求模型列出資料來源,但仍要親自開啟來源確認。因為模型可能提供過期資料、誤解原文,甚至產生看起來合理、實際上不存在的引用。
一個簡單的查證流程是:
當你熟悉基本操作後,可以開始把 LLM 放進固定流程,而不是每次都從空白對話開始。
例如撰寫文章時,可以依序請它協助:
真正能提升效率的,通常不是某一句神奇指令,而是一套可以重複使用、有人負責檢查的流程。
你可以使用以下六個元素組合指令:
例如,你可以這樣寫:
我正在撰寫一篇給台灣 AI 新手閱讀的 LLM 入門文章。請根據我提供的資料,整理出 5 個常見問題,每題用 100 至 150 字回答。使用自然的繁體中文,保留必要的英文專有名詞,不要使用中國用語。若資料不足,請標示「需要補充資料」,不要自行編造。
這種寫法比單純輸入「幫我寫 LLM 介紹」更容易得到符合需求的結果。
不過也不要把所有問題都歸咎於 prompt。結果不理想,也可能是模型能力不足、資料不完整、上下文太長、工具沒有連網,或任務本身需要專業判斷。
不同工具適合不同任務,不需要只看模型排名或參數大小。
你可以從以下幾個面向評估:
對一般使用者來說,最好的工具通常不是功能最多的工具,而是能穩定完成你的任務、資料政策可以接受,而且你知道怎麼檢查結果的工具。
對企業來說,還要進一步評估權限管理、身分驗證、稽核紀錄、資料分類、供應商風險、服務穩定性與法規遵循。
如果你只想記住幾個原則,可以從以下做法開始:
你也可以要求模型對自己的答案進行第二次檢查,例如:
這些做法不能保證完全正確,但能讓錯誤更容易被發現。
LLM 是一種擅長理解與生成語言內容的 AI 模型。它可以協助寫作、摘要、翻譯、學習、程式開發與企業知識管理,也正在改變許多人的工作方式。
但它產生的是根據模型、上下文與工具計算出的回答,不是經過保證的真相。回答流暢、內容完整或語氣有自信,都不能證明資訊一定正確。
對新手來說,最重要的不是背下所有技術名詞,而是建立正確的使用習慣:清楚描述任務、提供足夠資料、保護敏感資訊、檢查重要內容,並知道什麼時候需要回到官方來源或尋求專業人士協助。
只要掌握這些原則,LLM 就不只是聊天機器人,而會成為一個能協助你整理資訊、加快學習並改善工作流程的實用工具。
它能根據語言模式與上下文處理語意,表現得像是在理解你的問題,但這不代表它具有人類的生活經驗、意識或價值判斷。
在實際使用上,與其爭論它是否「真正理解」,更重要的是確認它能否穩定完成任務,以及結果是否經得起查證。
回答通常來自模型在訓練過程中學到的語言模式,以及你在當下對話中提供的內容。
如果產品支援搜尋、檔案讀取、資料庫、程式執行或其他工具,模型也可能使用這些外部資訊,但你需要確認該功能是否真的啟用。
它通常可以使用目前對話中的上下文,但不同產品對跨對話記憶、資料保存和個人化功能有不同設計。
不要因為模型似乎記得你的偏好,就假設它一定永久保存所有內容;同樣地,也不要假設關閉對話後資料一定立即消失。
常見差異包括可使用的模型、使用額度、回應速度、檔案限制、搜尋功能、圖片或語音能力,以及尖峰時段的可用性。
是否值得付費,取決於你的使用頻率與任務。如果只是偶爾摘要或發想,免費版本可能已經足夠;如果要處理大量文件、程式開發或工作流程整合,就要比較實際限制與成本。
技術上可以,但不應該只開通帳號就算完成導入。
企業至少要先定義可使用的資料範圍、禁止事項、人工審核責任、供應商政策、權限管理與事件處理方式,再從低風險、容易衡量的任務開始測試。
不一定。一般使用者可以先學會提問、提供資料、檢查答案與設計工作流程。
如果你想開發 AI 應用、串接 API、建立 RAG 系統、自行部署模型或研究模型訓練,程式能力才會變得更重要。
比較可能先被改變的,通常是工作中的部分任務,例如整理、初稿、分類、翻譯、客服回覆與程式輔助,而不是整個職業突然消失。
能否有效使用 AI、判斷結果、整合專業知識並承擔責任,可能會成為更多工作的基本能力。



