
Retrieval(檢索)發生在爬取、索引之後,排名之前,透過好的檢索,才能產生優質的搜尋體驗。

相較於常見的 Crawl(爬取)、Index(索引)、Ranking(排名),Retrieval(檢索)是比較少被討論到用詞,但 Retrieval 對於搜尋流程、RAG 來說,都有著非常重大的意義。
Retrieval(檢索)發生在爬取、索引之後,排名之前,透過好的檢索,才能產生優質的搜尋體驗。
本次就來好好聊聊 Retrieval(檢索),以及檢索在搜尋流程中扮演的角色。
在資訊檢索(Information Retrieval, IR)的語境裡,retrieval(檢索)指的是「在使用者提出查詢(query)之後,從已經建立好的索引(index)中找出最相關的文件或片段」的過程。
簡單理解,檢索(Retrieval)=「先把可能有用的東西先翻出來」的動作──就像你先把所有可能是鑰匙的東西倒在桌上,再細看哪一把能開門。而這些鑰匙就是前面 crawl、index 累積下來的材料。
包括:
傳統檢索方法多採用倒排索引 + BM25 / TF-IDF。
近年則大量使用向量檢索(embedding search)、雙階段檢索 (first-stage recall → reranker) 或在 RAG(Retrieval-Augmented Generation)管線中餵給大型語言模型。
延伸閱讀:《RAG 是什麼?白話文理解「檢索增強生成」對 SEO 與 AI 影響》
也分享一下 Retrieval 該怎麼發音,大概接近「re-tree-vul(瑞吹佛)」。
接下來我們來重新看一次搜尋流程(Search Process),並且挖掘檢索(retrieval)在其中扮演的角色。
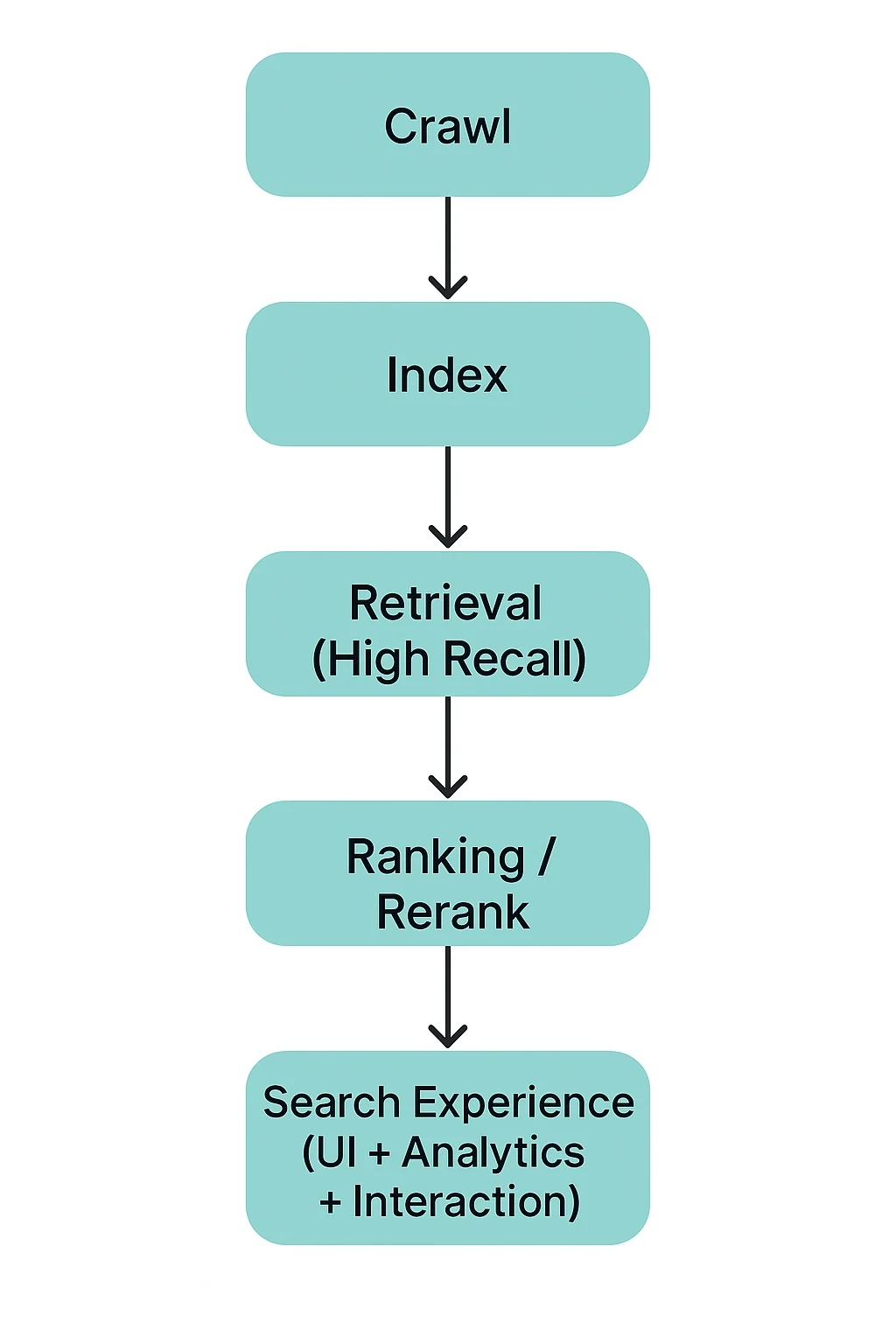
系統派出 crawler 或串接 API,按照連結或排程抓取網頁、PDF、影片字幕、資料庫內容等「原始素材」。
同時擷取時間戳、權重(PageRank 等)與 metadata,以便後續評分與更新。
沒有這一步就沒有「原料」;任何後續處理都無法進行。
將抓回來的文件做去重、解析、斷詞、欄位結構化與壓縮。
為關鍵字匹配建立倒排索引,為語意匹配計算向量並建立向量索引;也會紀錄文件長度、權威度等統計資料。
目的是把龐雜資料轉成「可在毫秒級隨機存取」的資料結構,為接下來的檢索提供速度保證。
使用者送出查詢後,系統先在索引中「廣撒網」抓出一批可能相關的候選文件(top-k,動輒數百~上千)。
技術上可結合倒排表(精確詞)與向量索引(語意),或用 Multi-Vector/Hybrid Search 提高召回。
這一步決定了上限:若文件在這裡被漏掉,後續再精巧的排名也救不回來。
在候選集上套用更昂貴、細膩的演算法:BM25 打分、學習排序(LTR)、BERT/MUM/LLM 交叉編碼器,甚至多層 rerank。
目標是把最相關、最可靠、最符合個人化意圖的結果排到前面,同時過濾低品質內容。
這一步通常是 RTB(Real-Time Bidding)、廣告插入或答案直接生成(如 RAG)的切入點。
延伸閱讀:《RAG 是什麼?白話文理解「檢索增強生成」對 SEO 與 AI 影響》
最終將排序好的結果以多樣形式呈現:傳統連結列表、Rich Snippet、常見問答框、Chat 回覆、即時卡片等。
這一層還會負責意圖澄清、拼字校正、建議查詢、互動式過濾器、統計圖表,甚至與語音/影像輸入整合。
好的體驗不只要「找得到」,還要「看得懂、點得到、用得快」,並回饋使用者行為給後端模型持續優化。
這是 Google 簡化後的搜尋三階段。
爬取(Crawling):Google 透過稱為「爬蟲」的自動化程式,在網際網路上尋找並下載網頁中的文字、圖片和影片。
索引(Indexing):Google 會分析這些文字、圖片與影片檔案,並將相關資訊儲存到龐大的 Google 索引資料庫。
提供搜尋結果(Serving search results):當使用者在 Google 上搜尋時,Google 會回傳與使用者查詢最相關的資訊。
延伸閱讀:《秒懂 Google 搜尋引擎運作原理:按下 Google 搜尋時發生什麼事?》
從上述的五階段,我們來對應 Google 的三階段。
在 Google SEO 的說明中心,中文版把 crawl 翻譯成「檢索」;把 crawler 翻譯成「檢索器」。

如果只在原本的「Crawling → Indexing → Serving」架構中倒沒問題,但如果希望進一步理解「 Indexing → ? → Serving」的過程,那把 Retrieval 的概念區別出來就很重要,如果把 Crawl 叫做爬取,那 Retrieval 就沒有詞可以用了。

在資訊檢索(Information Retrieval,IR)的流程裡,「Query Fan-Out」可以視為一種加強版的查詢策略,目標是提升召回率(recall)與結果多樣性。
兩者之間的關係,可用以下幾點來理解:
Retrieval 是整條管線中的「找資料」階段:給定一個原始查詢(或使用者提問),系統在索引或向量空間裡尋找最相關的文件/片段。
Query Fan-Out 則像是這個階段的「分身術」:在真正檢索前,先把單一路徑的查詢展開成多條平行路徑(fan-out),再各自送去檢索,最後把多路結果匯總。
Query Fan-Out 並不是另一個獨立步驟,而是嵌入在 retrieval 之前或之中的查詢生成/增強層。
延伸閱讀:《查詢擴展(Query Fan-Out )介紹:理解 Google AI 搜尋的重要技術》
語意覆蓋不足:單一向量或關鍵字可能抓不到同義詞、專有名詞縮寫、上下位概念。
長尾資訊:重要內容可能只在少數文件裡,必須透過不同視角的查詢才撈得到。
多模態/多語言:跨語言或跨格式檢索更容易漏掉關鍵線索,需要多樣化查詢補救。
優點:提高召回率、減少盲區、對偏長尾的知識庫特別有效。
成本:查詢次數倍增 → 計算與網路開銷上升;結果噪音變多,需要後續重排行(re-ranking)或過濾。
最佳實踐:通常先以較寬鬆的 fan-out 撈取候選集合,再用語言模型重排序、過濾或再檢索,兼顧成本與品質。
兩者相輔相成:沒有 fan-out,檢索可能漏掉關鍵文件;沒有高效的 retrieval,fan-out 產生的多條查詢也無法被快速解答。
把 Query Fan-Out 嵌入到 Retrieval 管線,可以在保持反應速度的前提下,顯著提升整體系統的資訊覆蓋率與答案品質。



