
如果 robots.txt 沒設定好,容易讓網站的爬取跟索引出大問題,是每個網站主、SEO 人都需要掌握的重要概念。

robots.txt 是網站跟 SEO 中一個很重要的概念。
如果 robots.txt 沒設定好,容易讓網站的爬取跟索引出大問題,是每個網站主、SEO 人都需要掌握的重要概念。
接下來就讓我們來簡單搞懂 robots.txt 是什麼吧!
robots.txt(爬蟲協議),是一種放在網站中的文本文件,這個文件會告訴爬蟲:哪些頁面可以爬、哪些頁面不可以爬。
從字面上你可以看的出來,它是由 robots(機器人)+txt(文本文件),也就是一個跟機器人(aka 爬蟲)溝通的文件。
robots.txt 跟搜尋引擎三階段的「爬取」大有關聯。
延伸閱讀:《爬取是什麼?》
因為我們不見得希望整個網站都被爬取,也不見得希望所有爬蟲來爬我們的網站,這就是管理爬取預算的重要性。
透過 robots.txt,我們就能跟搜尋引擎的爬蟲溝通我們的需求,而爬蟲就會參考我們設定的規範,來進行爬取。
延伸閱讀:《SEO 是什麼?如何高效自學 SEO?》
前面聊了這麼多 robots.txt,那這個對於我們操作 SEO 有何意義?
如果發現爬取有問題,確保 robots.txt 沒有封鎖到不該封鎖的網址。
像是以前某位政治人物網站上線時,就不小心將整個網站用 robots.txt 封鎖了,導致索引狀況非常差。
由於大型網站頁面太多,不是每個頁面都應該被爬取,此時利用 robots.txt 控制哪些區塊不應該爬取,節省搜尋引擎的時間、降低伺服器的負擔,就非常重要了。
robots.txt 會在網站根目錄的地方,而且一定要在這裡,以下列舉幾個知名網站的 robots.txt 位置。
你可以任意找一個網域,在根目錄輸入 robots.txt,就能找到對方的 robots.txt 了。
注意:robots.txt 必須要全部小寫,沒有特別的理由,就是行業規定。
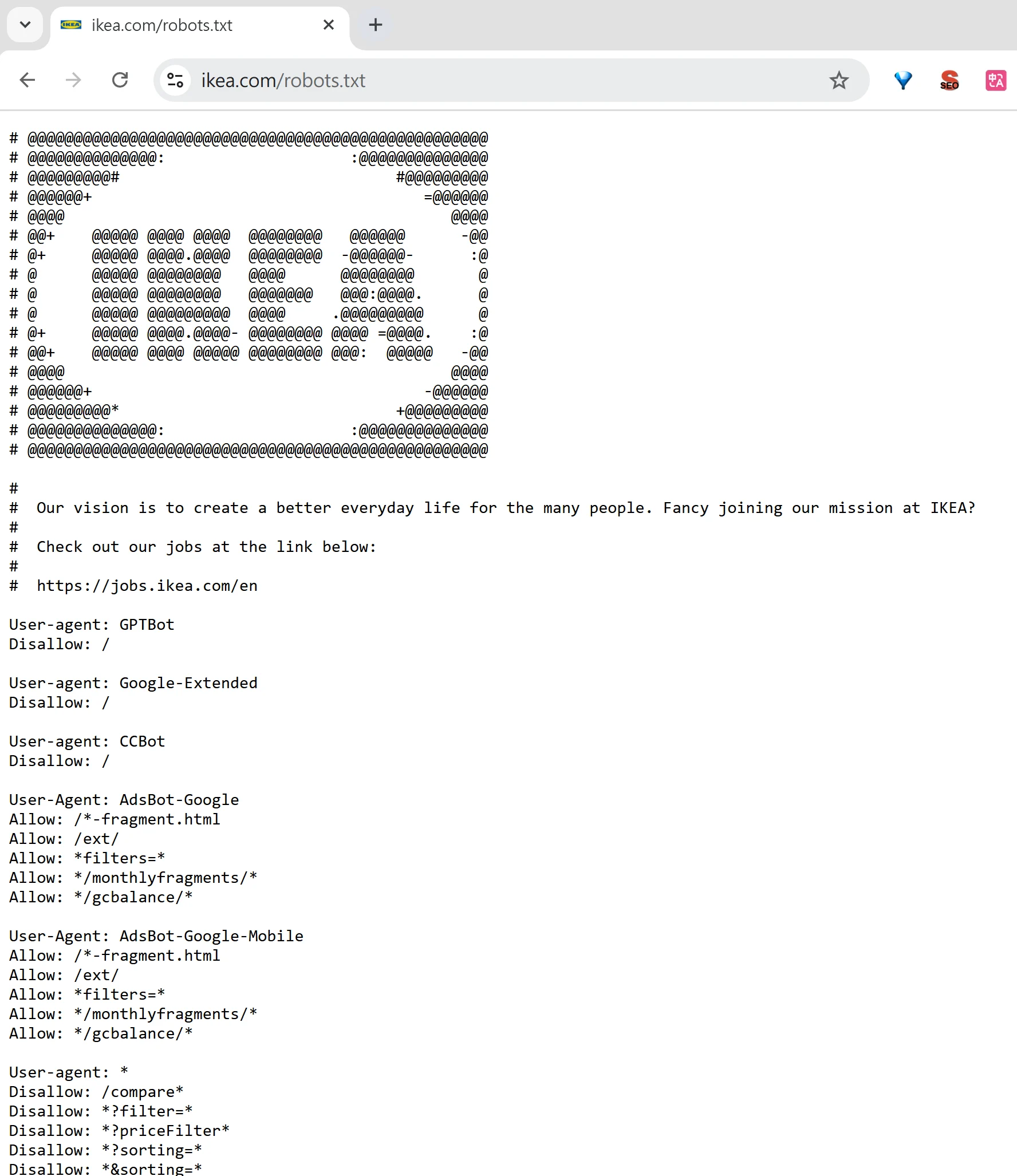
現在因為 AI 也會爬取網站內容來訓練模型,如果你不想要網站的內容被 AI 爬取的話,也能利用 robots.txt 來稍微防範。
User-agent: GPTBot
Disallow: /
工商時間
如果你想要更系統化、更輕鬆的學好 SEO,推薦你參考我與知識衛星合作的 SEO 線上課程《SEO 排名攻略學:從產業分析到落地實戰,創造翻倍流量》。
這是我的 SEO 集大成之作,讓你從入門到精通,附贈實戰模板跟檢核表,讓你真正學好 SEO。

這邊我用 Apple 官網的 robots.txt 來舉例,並且逐個解釋裡面的名詞。
連結:https://www.apple.com/robots.txt
# robots.txt for http://www.apple.com/
User-agent: *
Disallow: /*/includes/*
Disallow: /*retail/availability*
Disallow: /*retail/availabilitySearch*
Disallow: /*retail/pickupEligibility*
Disallow: /*shop/signed_in_account*
Disallow: /*shop/sign_in*
Disallow: /*shop/sign_out*
Disallow: /*shop/answer/vote*
Disallow: /*shop/bag*
Disallow: /*shop/browse/overlay/*
Disallow: /*shop/browse/ribbon/*
Disallow: /*shop/browse/campaigns/mobile_
我們可以看到,第一行寫了「# robots.txt for http://www.apple.com/」,這個是標示用途,非必要,讓我們知道這個 robots.txt 是為了 http://www.apple.com/ 這個網站所使用。
User-agent 你可以理解成網路世界中的名牌識別證。
當你使用瀏覽器(比如說 Chrome 或 Firefox)或其他的應用程式,去造訪一個網站時,你的裝置會向網站送出一個訊息:說明你是誰、你用的是什麼瀏覽器、你的裝置是什麼,甚至包括你的作業系統等等信息。
這個訊息就是 User-agent。
而爬蟲也會遵守的這個規則,以下則是常見的爬蟲 User-agent 名稱:
回到我們的案例,前面 Apple 官網中的「User-agent: *」就代表適用所有爬蟲,也就意味著以下規則(下面一堆的 disallow)適用於所有爬蟲。
下個部分我們看到:「Disallow: /*/includes/*」。
首先「Disallow」就是不允許的意思,代表 Disallow 後面的不允許爬取。
這邊我舉例,我們有一個網站是 example.com,這個網站裡面有以下的網址。
以下的 robots.txt 會代表這些意思。
舉例一:Disallow: /*
這代表 example.com/* 以後的網址都不能爬取,也就是整個網站都不能爬取。而這個「*」則是萬用符號的意思,它能代表任何字母及符號的意思,下方標示(X)代表爬蟲不能爬。
舉例二:Disallow:
這就是沒有規定什麼不能爬的意思,所以網址都可以爬;下方標示(O)代表爬蟲可以爬。
舉例三:Disallow: /*/includes/*
這代表 example.com/ 中包含 /includes/ 的都不能爬取。
舉例四:Disallow: /*retail/availability*
舉例五:如果使用 Apple 的 robots.txt:
Disallow: /*/includes/*
Disallow: /*retail/availability*
…
由於這些 Disallow 效果是取聯集,因此如果說 example.com 也按照上面 Apple 使用的 robots.txt,就會變成:
這意味著網站主不希望爬蟲去爬這些連結。
有 Disallow,那當然就有 Allow。
同樣是 Apple 官網的 robots.txt 文件中,我們可以找到:
User-agent: Sogou web spider
Disallow: /*
Allow: /cn/*
Allow: /cn-k12/*
現在你應該幾乎都能看懂了吧!讓我來替你翻譯一下。
翻譯:針對 Sogou web spider 這個 User-agent,整個網站都不能爬取,但允許爬取:「/cn/*」、「/cn-k12/*」路徑的網頁。
現在是不是已經能看懂 robots.txt 文件了呢?
或許你會想,那如果這兩種指令衝突、矛盾會怎麼辦呢?好比說以下的例子:
User-agent: Sogou web spider
Disallow: /*
Allow: /cn/*
Allow: /cn-k12/*
這個例子中,為何 Allow 可以不受前面的 Disallow 的約束呢?不是說好整個網站都爬嗎?
這邊我們可以參考 Google 官方的說法:
「將 robots.txt 規則與網址比對時,檢索器會根據規則路徑長度,使用最明確的規則。如果規則發生衝突(包括含有萬用字元的規則),則 Google 會使用限制最少的規則。」
這邊我們使用幾個 Google 提供的舉例:
舉例一:https://example.com/page
allow: /p
disallow: /
適用規則:allow: /p,因為規則較為明確。
舉例二:https://example.com/folder/page
allow: /folder
disallow: /folder
適用規則:allow: /folder,因為在規則發生衝突的情況下,Google 會使用限制最少的規則。
而這種狀況算是比較不理想的情況,建議網站主不要規劃這種規則,會讓搜尋引擎比較困惑。
如果你想要檢測自己網站的 robots.txt 有沒有設定好,你可以透過 Google 官方工具《使用 robots.txt 測試工具檢測 robots.txt》,查看 Google 能否處理你的 robots.txt 檔案。
robots.txt 只能放在根目錄,就是網址的最淺那一層,舉例:
關於上傳的方法,每個網站方法不太相同,你可以與你的網站公司聯絡、工程師聯絡,討論如何上傳。
理論上網站應該原本就有設定好 robots.txt 了。
上傳到正確的根目錄後,Google 會自動抓取到 robots.txt 的規則,不需要額外做什麼。
提醒:如果是不同子網域,那都需要額外設定每個子網域的 robots.txt。
如果你認為網站某些頁面完全沒有被爬取跟索引的價值,你也不希望這些內容出現在搜尋結果頁上,像是某些標籤頁、搜尋結果頁,那麼可以把那些網址路徑加入 robots.txt 當中。
如果你的網站並不大,一般來說只須要 robots.txt 擋到不該擋的頁面,而不是主動去阻擋爬蟲爬取網站。
有的情況下,我們網站會一些不希望被 Google 爬取跟索引的資料,我們是否能用 robots.txt 來禁止呢?
有關於這個問題,理論上可以,但在實務上卻非常不建議,我提供以下建議給你參考。
由於 robots.txt 並非強制性,爬蟲們會「尊重」規則,但還是會遇到耍流氓的情況。
因此儘管 robots.txt 看似可以避免敏感資料被爬蟲爬取,但並非很安全的方法。
Google 官方說明:
「警告:如果不想讓網頁顯示在 Google 搜尋結果中,請不要以 robots.txt 做為隱藏網頁 (包括 PDF 和其他 Google 支援的文字格式) 的方法。
如果有其他網頁的說明文字指向您的網頁,即使 Google 未造訪您的網頁,還是能夠為網頁建立索引。
如要防止自己的網頁顯示在搜尋結果中,請使用其他方法,例如密碼保護或是 noindex 標記。」
完整討論:《為什麼 robots.txt 與 noindex 不能同時使用?》
robots.txt 文件是公開的,任何人都可以查看它,就像是我們可以分析 Apple 官網的 robots.txt 一樣,任何人都可以點這個連結來了解。
因此你如果在 robots.txt 文件中列出敏感的路徑,實際上反而是揭露了敏感資訊。
敏感頁面這件事本質是資安問題,不算是 SEO 問題,因此我會建議你不要單純靠 SEO 解決它,請尋求專業工程人員的協助,讓網站跟客戶的資料能被安全的保護。
工商時間
如果你想要更系統化、更輕鬆的學好 SEO,推薦你參考我與知識衛星合作的 SEO 線上課程《SEO 排名攻略學:從產業分析到落地實戰,創造翻倍流量》。
這是我的 SEO 集大成之作,讓你從入門到精通,附贈實戰模板跟檢核表,讓你真正學好 SEO。
robots.txt 是放在網站中的文字檔,用來告訴爬蟲哪些頁面可以爬、哪些頁面不可以爬,是網站跟爬蟲溝通規則的檔案。
因為不一定希望整個網站都被爬取,也不一定希望所有爬蟲都來爬;透過 robots.txt 可以表達需求、管理爬取範圍,進而控制爬取預算。
首先要確保 robots.txt 沒有封鎖到不該封鎖的網址,避免影響爬取與索引;大型網站則可用 robots.txt 控制哪些區塊不應該爬取,節省搜尋引擎時間並降低伺服器負擔。
robots.txt 一定在網站根目錄,通常在網域後面加上 /robots.txt 就能看到。檔名必須全部小寫(行業慣例)。
可以稍微防範,做法是針對特定 AI 爬蟲的 User-agent 設定規則,例如:User-agent: GPTBot 搭配 Disallow: /,表示不允許 GPTBot 爬取整個網站。
User-agent 可以理解成網路世界中的識別資訊,告訴網站「你是誰、用什麼程式/裝置」;爬蟲也會使用自己的 User-agent。像 User-agent: * 代表適用所有爬蟲。
Disallow 代表不允許爬取其後指定的路徑;* 是萬用字元,可代表任何字母與符號。像 Disallow: /* 代表整站都不能爬;Disallow: (空白)代表沒有禁止任何路徑;Disallow: //includes/ 代表包含 /includes/ 的網址不能爬。多條 Disallow 的效果會取聯集,符合任一條就會被擋。
不建議只靠 robots.txt。原因是 robots.txt 並非強制性,可能遇到不遵守規則的爬蟲;而且 robots.txt 是公開的,把敏感路徑寫進去反而像是在揭露敏感資訊。若不想出現在搜尋結果不要用 robots.txt 隱藏網頁,應改用密碼保護或 noindex 等方法;敏感資料本質上是資安問題,建議找工程與資安人員處理。



