
在搜尋引擎三階段中,爬取(Crawl)是第一階段,也是許多網站技術人員、SEO 技術人員最常鑽研的面向,也是 SEO 的重要起點。

在搜尋引擎三階段中,爬取(Crawl)是第一階段,也是許多網站技術人員、SEO 技術人員最常鑽研的面向。
當一個網站爬取做得好,就容易被索引,也就有機會獲得好排名。
特別是大型網站,由於網頁內容太多了,要怎麼確保網站的重要內容都能被搜尋引擎爬蟲輕鬆爬完,就是大型網站 SEO 人員的必修課題。
接下來就讓我們來了解爬取,以及要如何做好爬取吧。
我們已經知道了搜尋引擎要爬取網站,那實際上要靠什麼東西來「爬」呢?
答案就是「爬蟲」,英文叫做「Crawler」跟「Spider」。
「網路」中的「網跟路」、「Internet」中的「net」,裡面都有網狀的概念,每個網頁透過連結串聯成一個網子,連結就是那條線。
透過頁面跟連結,進而組成了整個網際網路,而這些爬蟲就像是在網子上移動的蜘蛛,把每個網頁都瀏覽過一次。
延伸閱讀:《秒懂 Google 搜尋引擎運作原理:按下 Google 搜尋時發生什麼事?》
爬取預算(檢索預算)是一個爬取中重要的概念,你可以當成 Google 會配一個網站每天固定的爬取額度,用完就沒了。
因此我們要把這些額度都用在最重要的網頁上。
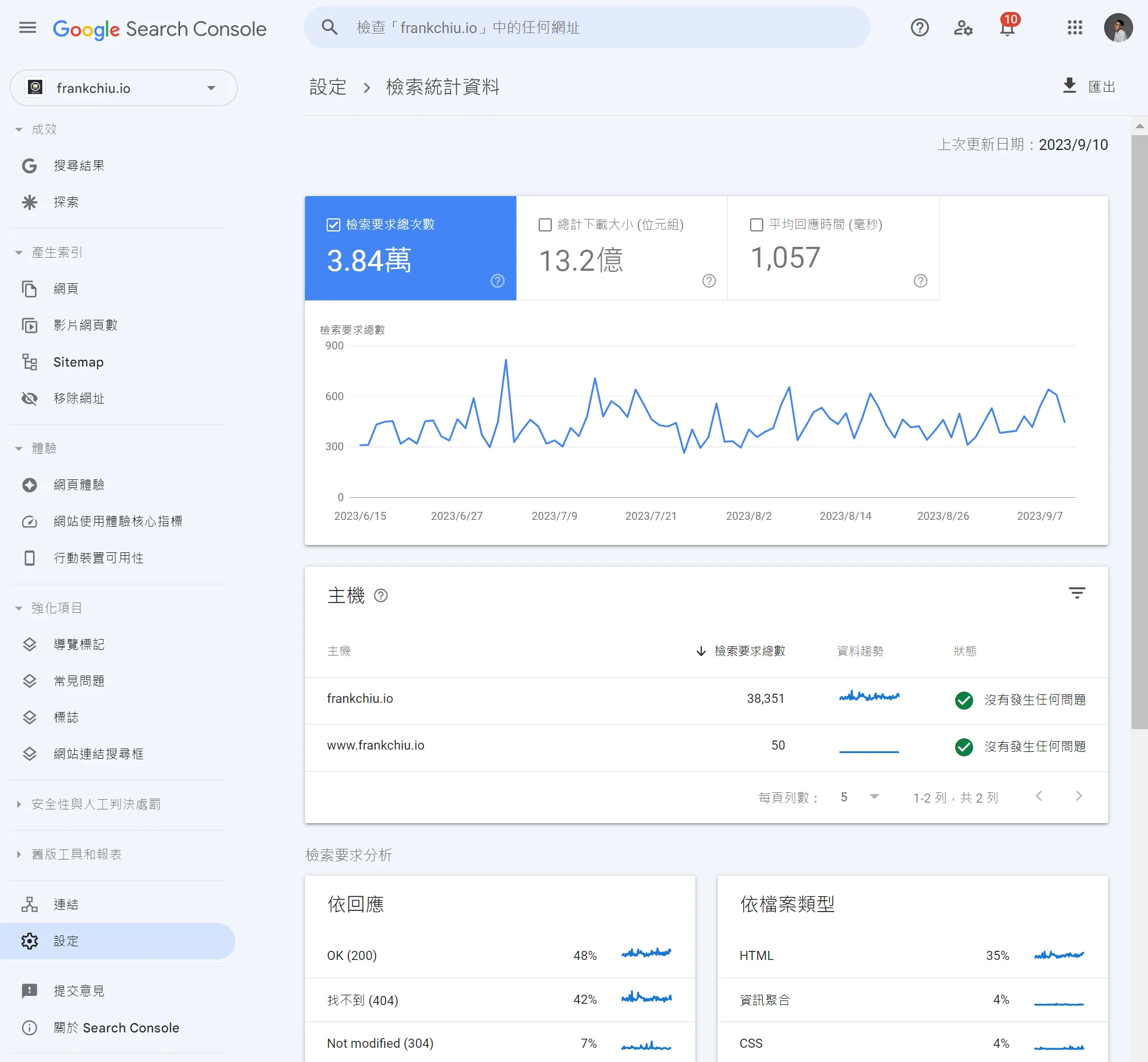
我們可以從 Google Search Console 中的「設定>檢索>檢索統計資料」,來得知 Google 對於我們網站的檢索次數,評估 Google 對於網站的爬取狀況。
這邊的檢索次數可以讓我們了解爬取預算的多寡,當我們發現 Google 檢索網站的次數變少了,可能要留意 Crawl Budget 可能變少了。
如上面這張圖就是我的檢索統計資料,可以看到在 90 天內我的網站被 Google 爬取(檢索)3.84 萬次,平均一天約莫 400 多次。
而我整個網站網頁約莫 380 頁,這樣的次數是沒問題的。
但如果我的網站有 40,000 頁,但每天只有爬取 400 次,那問題就大了,代表爬取預算不足,需要進行調整。
延伸閱讀:《SEO 自學大全:一篇就搞懂 SEO,完整說明 SEO 的底層邏輯》
大型網站需要特別注意爬取預算,因為網頁太多了、要確保重要的網頁都能被即時爬取跟更新。
像是蝦皮、momo 這類大型電商網站,都很注重爬取預算的控制。
根據 Google 官方說法,以下狀況者需要特別注意爬取預算:
如果你是大型網站的網站主,推薦你閱讀 Google 官方提供的《大型網站擁有者的檢索預算管理指南》。
工商時間
如果你想要更系統化、更輕鬆的學好 SEO,推薦你參考我與知識衛星合作的 SEO 線上課程《SEO 排名攻略學:從產業分析到落地實戰,創造翻倍流量》。
這是我的 SEO 集大成之作,讓你從入門到精通,附贈實戰模板跟檢核表,讓你真正學好 SEO。

爬蟲儘管很厲害,但爬蟲也會有一些限制,主要原因就是上面提到的爬取預算有限制。
網海無盡,爬蟲必須省時省力,把資源放在重要的頁面上。
以下的頁面容易造成爬蟲的負擔、或是讓爬蟲無法工作,網站主要特別注意。
有些頁面會限制爬蟲進入,像是某些付費牆內容,只有獲得權限的人可以進去,爬蟲這個時候會被擋在外面。
網站主可以透過 robots.txt 設定,告訴爬蟲哪些頁面可以爬、哪些頁面不能爬,爬蟲原則上會遵守此規則。
好比說有些情況,網站主會限制特定爬蟲進入網站,因為這些爬蟲對於網站伺服器都是額外的負擔,有些網站主為了網站穩定性會限制特定爬蟲來爬取,把爬蟲擋在門外。
延伸閱讀:《robots.txt 介紹:什麼是 robots.txt?》
如果網站結構很糟糕,網站內部連結稀疏,導致爬蟲「無路可走」,那自然就很難把整個網站走透透;因此增加網站的內部連結很重要。
延伸閱讀:《網站架構優化:什麼是 SEO 友善的網站架構?》
當我們在路上塞車時,就很難開車暢遊整個城市。
回到爬蟲的狀況也是相同,如果一個網站很卡,每頁載入都塞車,那麼爬取效率也會大打折扣,搜尋引擎也會認為這樣的頁面使用者會提供負面的回饋。
延伸閱讀:《網頁速度(Page speed)是什麼?網站速度如何優化?》
JavaScript 網頁對於搜尋引擎來說是較難解析的網頁,由於 Google 爬蟲在近年持續進步,JavaScript 網站的爬取跟索引已經有所改善。
但相較於一般 html 網頁,JS 的頁面對於爬蟲來說會更吃力,需要做更多額外優化。
透過上述內容,我們已經理解了哪些狀況對於爬蟲會造成負面影響,那麼我們要做的就是將其反轉,就能創造好的爬蟲體驗了。
好比:
而從這些內容我想你也能感受到,Google 就是希望越舒服越好,希望可以越快、越輕鬆、越容易的爬完網站,那就越好。
另一方面,優化爬取就是在優化 Crawl Budget,讓預算花在重要的頁面、讓預算可以花得更有效率,並且把不重要的頁面隔離,避免消耗爬取預算。
後續我也會分享更多優化爬取的方法。
工商時間
如果你想要更系統化、更輕鬆的學好 SEO,推薦你參考我與知識衛星合作的 SEO 線上課程《SEO 排名攻略學:從產業分析到落地實戰,創造翻倍流量》。
這是我的 SEO 集大成之作,讓你從入門到精通,附贈實戰模板跟檢核表,讓你真正學好 SEO。



