
本文將以初學者也能理解的方式,逐步拆解 BM25 的計分原理、與 TF-IDF 的差異,幫助你更了解系統是如何判別內容相關度。

每秒有將近 19 萬次 Google 搜尋正在發生,而這些查詢在進入 AI 摘要、向量檢索或其他複雜排序模型之前,都要先經過一個「關鍵字吻合度快篩」,而業界最常用的就是 BM25(Okapi BM25)。
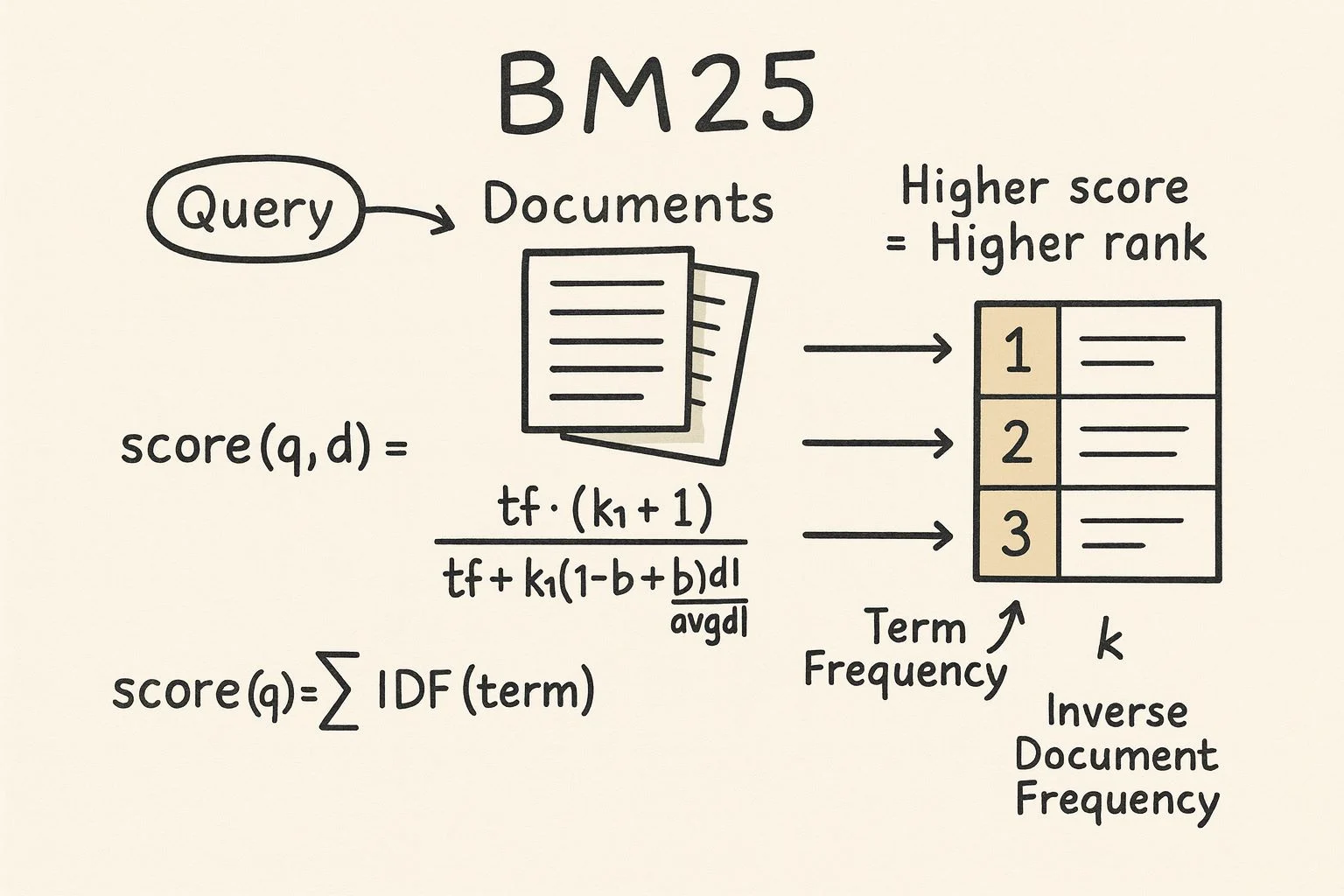
BM25 先讀取使用者的查詢(一串關鍵字),再檢查每篇文件(網頁、新聞、PDF …)裡這些關鍵字的出現次數(詞頻)、在全庫的罕見度(逆文件頻率),並校正文件長度,最後算出一個相關度分數。分數越高,文件越有機會晉升到搜尋結果前排。
對 SEO 人員而言,BM25 就是搜尋排名的第一道門檻:只有在這一步拿到合格分數,內容才會被送進後續的語意模型或大型語言模型,爭取更高的曝光順位。
本文將以初學者也能理解的方式,逐步拆解 BM25 的計分原理、與 TF-IDF 的差異,幫助你更了解系統是如何判別內容相關度。
BM25(全名 Okapi BM25)是一種「機率式文字比對公式」,搜尋系統使用它來計算一篇文件——在這裡文件可以是網頁、新聞或 PDF——與使用者下的查詢(也就是搜尋關鍵字組合)之間的相關程度。
整套方法建基於「機率檢索模型」:它假設越相關的文件,越有可能同時包含查詢裡的詞,而越不相關的文件,包含這些詞的機率就越低。
它會同時考慮三件事:
把這些因素加權後,BM25 產生一個分數,分數越高就代表文件越可能是使用者正在找的內容,搜尋系統便能依此把相關度高的結果排到前面。
BM:Best Matching(最佳匹配),出自英國 City University London 開發的 Okapi 專案。
25:僅僅是版本號,在 1990 年代 Okapi 團隊試驗了數十種權重函式(BM1、BM11、BM15…),把當時表現最好的第 25 號公式發表並沿用,所以就叫 BM25。
Google 雖然在 2016 之後陸續加入 RankBrain、BERT、RankEmbed 等大型機器學習訊號,但工程師公開資料指出:傳統的 Okapi BM25 仍是最早用來計算初步相關度的基礎函式,再與機器學習特徵混合成混成式(hybrid)排序。若你的內容在 BM25 階段就被過濾掉,就輪不到後面更智慧的模型評分。
混成式排序:先用傳統關鍵字模型快篩文件,再用語意或點擊訊號重新排列,以兼顧速度與品質。
BM25 中的 TF(Term Frequency)分數會隨出現次數遞減;重複塞同一關鍵字到極高密度不會再帶來額外分數。相反地,選用 IDF 較高的長尾關鍵字(較少網站使用、但與主題密切相關的詞)更能提升相關度。
掌握這些原理有助你寫出自然、非堆砌的內容,同時提高排名機會。
2025 年各大搜尋與 LLM 產品普遍採用「先 BM25 取候選 → 再用向量或 LLM 生成摘要/回答」的 RAG(Retrieval-Augmented Generation)框架。
若你的內容無法在 BM25 階段進入候選集,就無法被 LLM 摘要或引用。
熟悉 BM25 是 GEO(Generative Engine Optimization) 的基礎。
在計算過程中,BM25 需要先認識幾個基本量。
詞頻(Term Frequency, TF)指的是某個關鍵詞在單一文件內出現的次數;只要出現一次,TF = 1,出現十次,TF = 10。雖然次數增加通常代表該詞很重要,但 BM25 會把過高的 TF 逐漸「壓抑」,因為出現一百次並不代表真的重要一百倍。
接著是逆文件頻率(Inverse Document Frequency, IDF)。系統會先掃描整個語料庫(corpus),計算每個詞出現在多少篇文件裡;若一個詞很少文件用到,它的 IDF 就高,表示「稀有而關鍵」,計分時就能得到較大權重;相反,像「and」或「的」這些高頻詞,IDF 值接近零,幾乎不加分。
BM25 還加入文件長度正規化。
同一個詞在長篇文章中本來就可能自然出現得比較多,所以系統會用一個參數 b(常見預設 0.75)把長文件的分數稍微調低、把極短文件的分數稍微調高,以避免篇幅差異讓短文永遠排不進搜尋結果前列。
另一個參數 k₁(常見介於 1.2 到 2.0)則控制 TF 壓抑的幅度:k₁ 越大,TF 影響越線性;k₁ 越小,飽和效果越快。
經過 TF、IDF 與長度正規化三步調整後,BM25 會為查詢中的每個詞算出一個分數,再把它們相加成為最終的相關度分數。
使用者送出查詢時,搜尋系統就依照這個分數對所有候選文件排序,分數越高的文件越先顯示。由於公式計算快速、效果穩定,直到 2025 年它仍被廣泛用作「第一層篩選」:先以 BM25 把不相關的文件排除,再交給語意向量或大型語言模型做更深入的判斷。
想像你走進一間超大圖書館,要替朋友找到「貓咪自製點心」的食譜:
BM25 就是把這三件事做成一個「打分公式」,幫搜尋引擎把最相關的書排到最前面。

就像數「貓咪」在食譜裡被提到幾次。出現越多,代表這篇文章跟「貓咪」關係越大。
這個數字在公式裡寫作 f(qi, D)(qi 是第 i 個關鍵字)。
如果整座圖書館只有少數書提到「貓咪」,那看到「貓咪」時就應該大加分。
這種「稀有度」叫 IDF,專門獎勵罕見但關鍵的詞。
一本 500 頁的書一定比 50 頁的書多重複幾次關鍵字;為了公平,要對長書做「扣分」。
公式會用 |D|(文件長度)對比全庫平均長度 avgdl,再用參數 b(預設 0.75)決定扣多少。
同一個詞出現到第 3、4、5 次後,再加分也要慢慢變少,避免無限疊加。
這就靠參數 k1(通常 1.2–2.0)來調,值大=重複仍加分,值小=很快進入「不再加太多」的飽和區。
查詢可能有好幾個詞(例如「貓咪」+「點心」),先分別計分,再全部相加,就得到這篇文件的總分;分數越高,搜尋結果排名越前面。
如果你也看過我前一篇討論 TF-IDF 的文章,你會發現上述很多概念很相像,但 TF-IDF 與 BM25 卻也有差異,以下詳細說明。
近年多份實驗顯示,在長文件或多主題語料上,BM25 通常能比 TF-IDF 找到更符合使用者意圖的結果,因此被業界當成「快速且可靠的第一層篩選」;後端若要再接語意向量或 RAG 系統,也多半先用 BM25 把候選集縮小。
TF-IDF 是「詞越多分越高」的簡易加權。而 BM25 則在此基礎上加了飽和與長度調整兩道保險,再透過可調參數把計分結果貼近真實閱讀習慣,所以在 2025 年的搜尋和 RAG 管線中仍是主流基線。



